

Növelje készségeit a Growth Memo heti szakértői betekintéseivel. Iratkozz fel ingyen!
Ezen a héten megosztom az 1,2 millió ChatGPT-válasz elemzése során szerzett eredményeimet, hogy megválaszoljam azt a kérdést, hogyan lehet javítani az idézettség esélyeit.
A keresőoptimalizálók 20 éve írnak „végső útmutatókat”, amelyek célja, hogy az embereket az oldalon tartsák. Hosszú bevezetőket írunk. A betekintést végighúzzuk a tervezeten és a következtetésen keresztül. Feszültséget építünk az utolsó cselekvésre való felhívásra.
Az adatok azt mutatják, hogy ez az írásmód nem ideális az AI láthatóságához.
1,2 millió ellenőrzött ChatGPT-idézet elemzése után olyan következetes mintát találtam, hogy P-értéke 0,0: a „sífelhajtó”. A ChatGPT aránytalanul nagy figyelmet fordít a tartalom felső 30%-ára. Ezenkívül öt egyértelmű jellemzőt találtam az idézett tartalomnak. Ahhoz, hogy nyerni tudj az AI-korszakban, el kell kezdened úgy írni, mint egy újságíró.
1. A szöveg mely részeit idézi a legnagyobb valószínűséggel a ChatGPT?
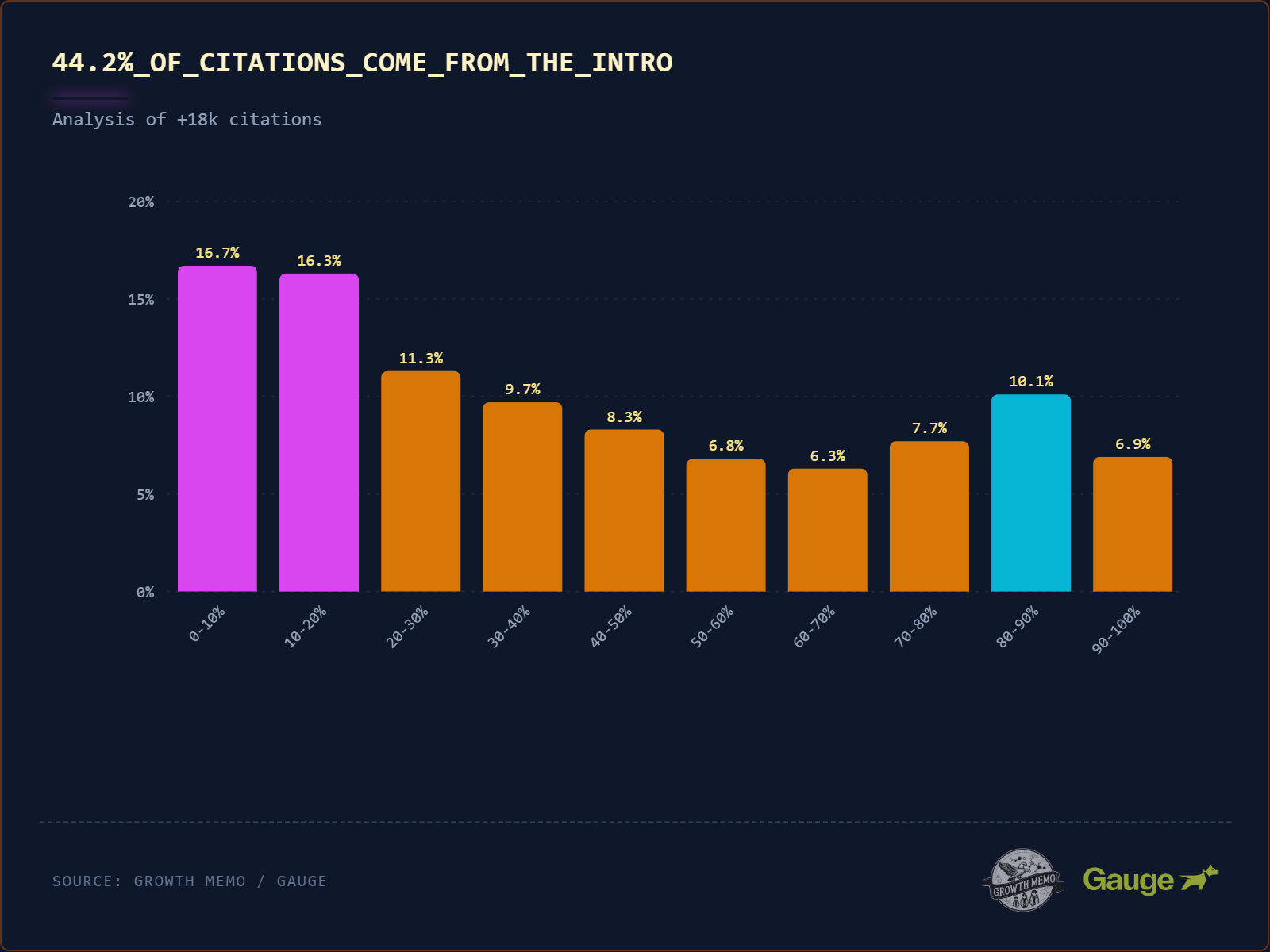
Nem sokat tudni arról, hogy az LLM-ek a szöveg mely részeit idézik. 18 012 idézetet elemeztünk, és találtunk egy „sírámpás” eloszlást.
- Az összes idézet 44,2%-a a szöveg első 30%-ából származik (a bevezető). Az AI úgy olvas, mint egy újságíró. Felülről megragadja a „Ki, mit, hol” feliratot. Ha kulcsfontosságú meglátása a bevezetőben található, nagy az esélye annak, hogy idézik.
- Az idézetek 31,1%-a a szöveg 30-70%-ából származik (középről). Ha a legfontosabb termékjellemzőket egy 20 bekezdésből álló bejegyzés 12. bekezdésébe temeti, az AI 2,5-szer kisebb valószínűséggel hivatkozik rá.
- Az idézetek 24,7%-a egy cikk utolsó harmadából származik (a következtetés). Ez bizonyítja, hogy a mesterséges intelligencia felébred a végén (hasonlóan az emberekhez). Kihagyja a ténylegeset lábléc (lásd a 90-100%-os kiesést), de szereti a lábléc előtti „Összefoglaló” vagy „Következtetés” részt.
A sírámpa mintázatának lehetséges magyarázata az edzés és a hatékonyság:
- Az LLM-eket újságírásra és tudományos dolgozatokra képezik, amelyek a „BLUF” (Bottom Line Up Front) struktúrát követik. A modell megtanulja, hogy a leginkább „súlyozott” információ mindig a tetején van.
- Míg a modern modellek akár 1 millió tokent is képesek kiolvasni egyetlen interakcióhoz (~700 000-800 000 szó), céljuk a keret lehető leggyorsabb létrehozása, majd minden más értelmezése a kereten keresztül.
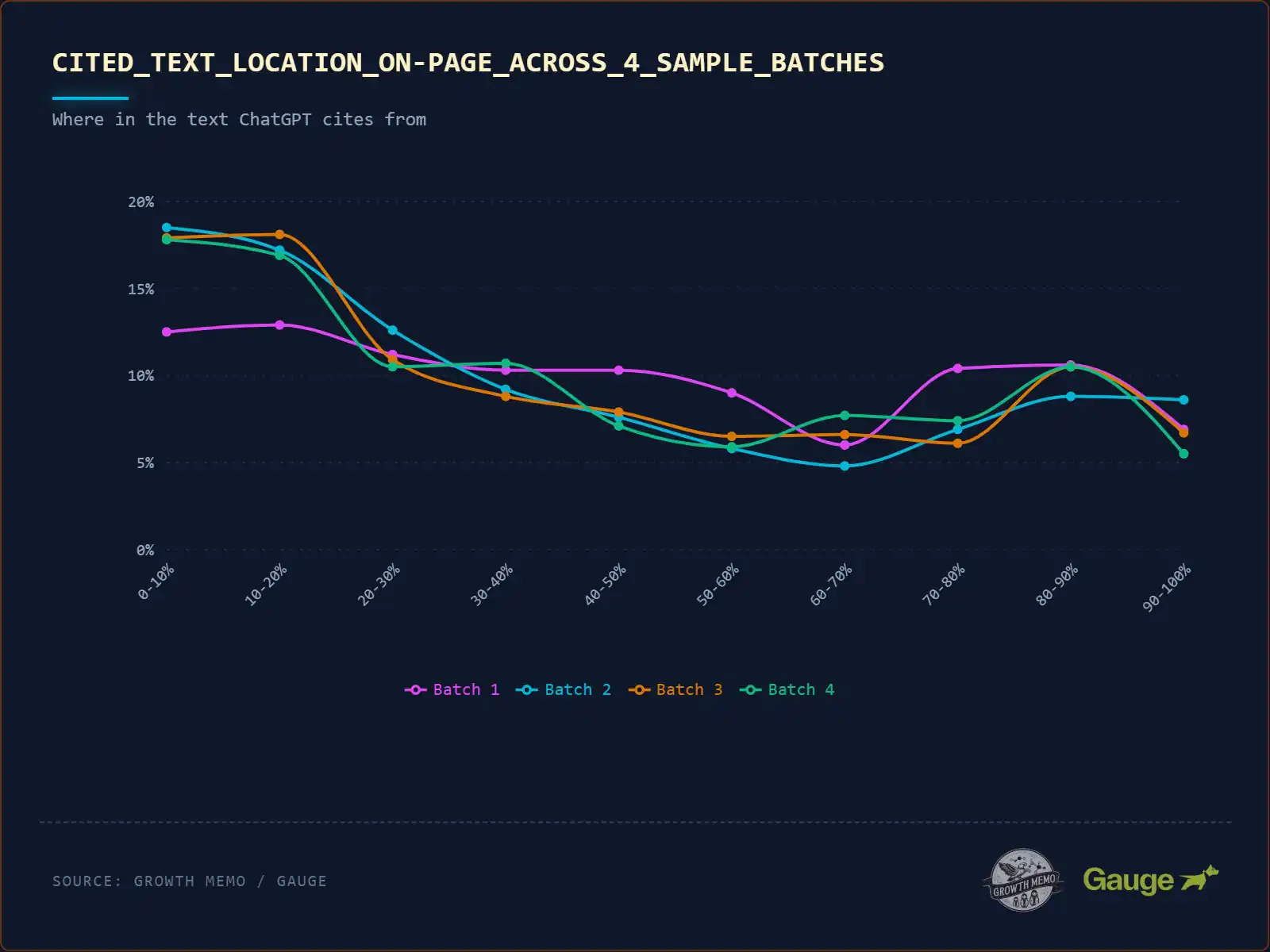
Az 1,2 millió idézetből 18 000 megadja nekünk a szükséges betekintést. Ennek az elemzésnek a P-értéke 0,0, vagyis statisztikailag vitathatatlan. Az eredmények stabilitásának demonstrálására az adatokat kötegekre bontottam (randomizált validációs felosztások).
- Az 1. köteg kissé laposabb volt, de a 2., 3. és 4. köteg majdnem azonos.
- Következtetés: Mivel a 2., 3. és 4. köteg pontosan ugyanarra a mintára volt rögzítve, az adatok mind az 1,2 millió idézetben stabilak.
Noha ezek a kötegek megerősítik a makroszintű stabilitást, hogy a ChatGPT hol tekint át egy dokumentumon, új kérdést vetnek fel a részletes viselkedésével kapcsolatban: ez a rendkívül erős torzítás még egyetlen szövegblokkon belül is megmarad, vagy az AI fókusza megváltozik, amikor mélyebben olvas? Miután megállapítottam, hogy az adatok skálán statisztikailag vitathatatlanok, szerettem volna „nagyítani” a bekezdés szintjére.
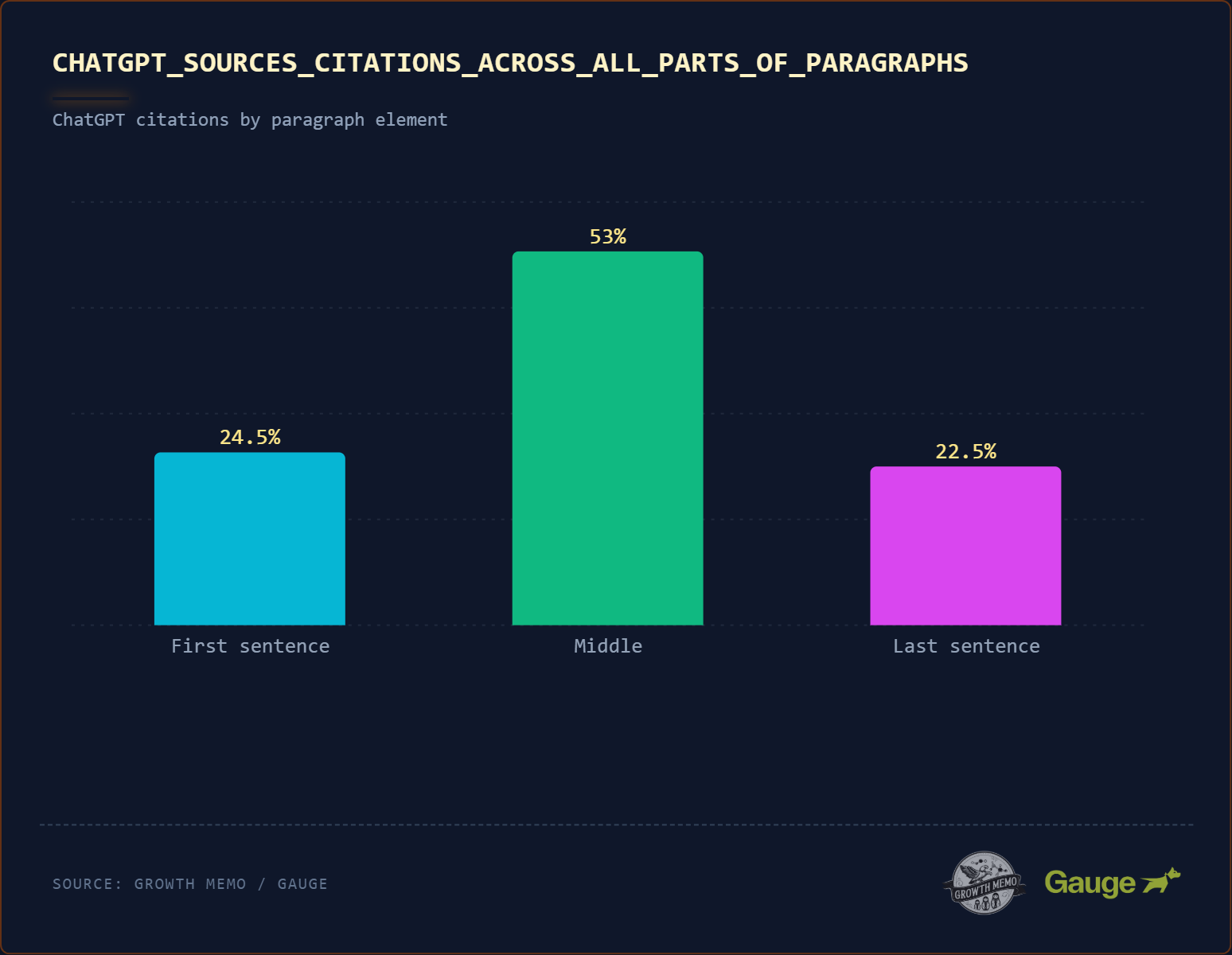
1000 tartalom nagy mennyiségű idézetet tartalmazó mélyelemzése azt mutatja, hogy az idézetek 53%-a egy bekezdés közepéről származik. Csak 24,5% származik egy bekezdés első, 22,5% pedig az utolsó mondatából. A ChatGPT nem „lusta”, és csak minden bekezdés első mondatát olvassa el. Mélyen olvas.
Elvihető: Nem kell minden bekezdés első mondatába beleerőltetni a választ. A ChatGPT a legmagasabb „információnyereséggel” rendelkező mondatot keresi (a releváns entitások és az additív, kiterjedt információk legteljesebb használata), függetlenül attól, hogy ez a mondat az első, a második vagy az ötödik a bekezdésben. A sírámpa mintájával kombinálva arra a következtetésre juthatunk, hogy az oldal első 20%-ában található bekezdések adják a legnagyobb esélyt az idézetekre.
2. Mitől valószínűbb, hogy a ChatGPT darabokat idéz?
Tudjuk ahol a tartalomban a ChatGPT szeret idézni, de melyek azok a jellemzők, amelyek befolyásolják az idézés valószínűségét?
Az elemzés öt nyerő tulajdonságot mutat be:
- Meghatározó nyelv.
- Beszélgetési kérdés-felelet szerkezet.
- Az entitás gazdagsága.
- Kiegyensúlyozott hangulat.
- Egyszerű írás.
1. Végleges vs. Homályos nyelv
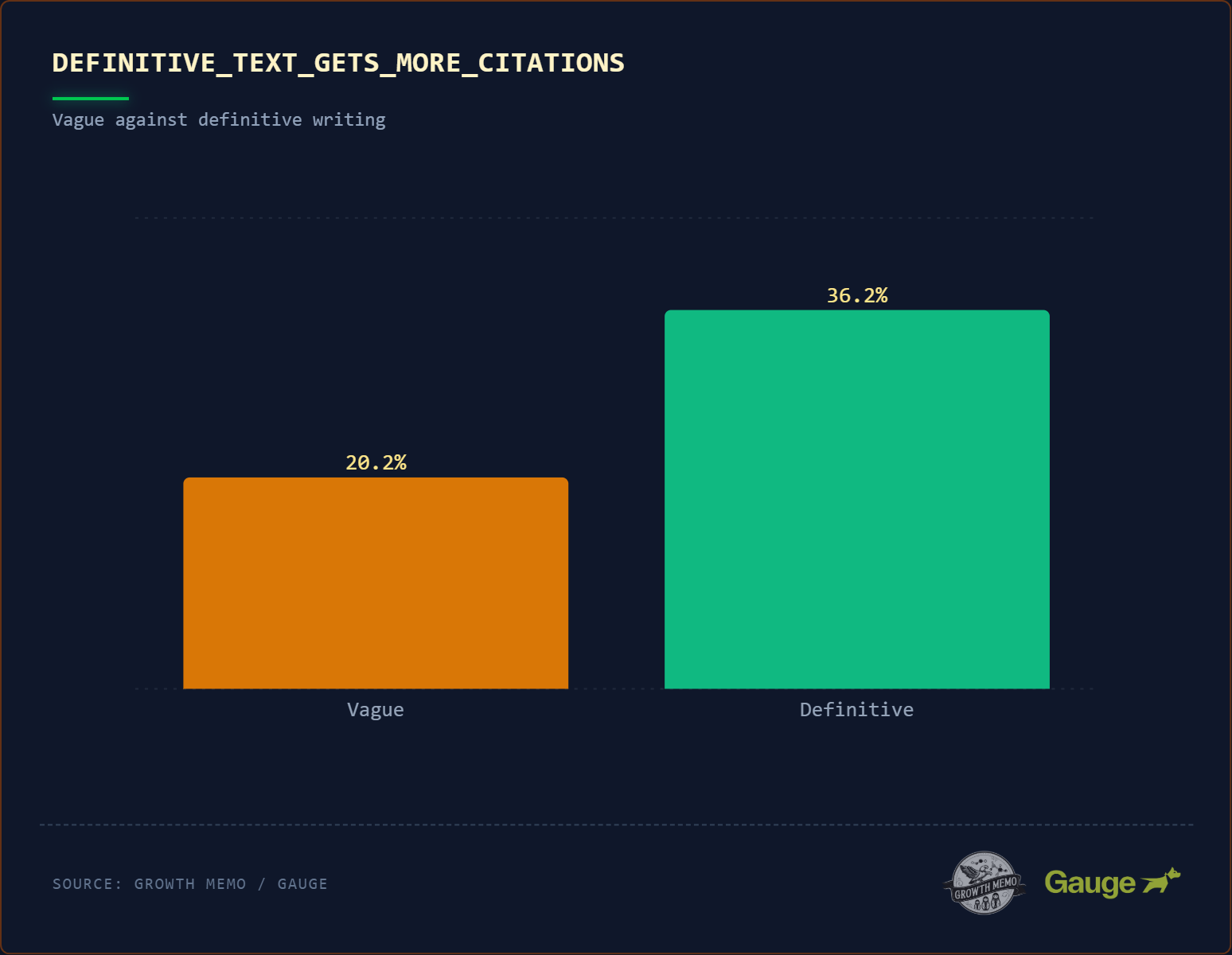
Az idézetek nyertesei majdnem kétszer nagyobb valószínűséggel (36,2% vs 20,2%) tartalmaznak határozott nyelvezetet („úgy van meghatározva”, „utal”). A nyelvi idézetnek nem kell szó szerinti definíciónak lennie, de a fogalmak közötti kapcsolatoknak egyértelműnek kell lenniük.
A közvetlen, deklaratív írás hatásának lehetséges magyarázatai:
- Egy vektoros adatbázisban az „is” szó erős hídként működik, amely összeköti az alanyt a definíciójával. Amikor a felhasználó megkérdezi: „Mi az X?” a modell a legerősebb vektorutat keresi, ami szinte mindig direkt „X az Y” mondatszerkezet.
- A modell megpróbál azonnal válaszolni a felhasználónak. Olyan szöveget részesít előnyben, amely lehetővé teszi a lekérdezés egyetlen mondatban történő feloldását (Zero-Shot), ahelyett, hogy öt bekezdésből szintetizálná a választ.
Elvihető: Kezdje cikkeit közvetlen kijelentéssel.
- Bad: „Ebben a felgyorsult világban az automatizálás kulcsfontosságúvá válik…”
- Jó: „A demóautomatizálás az a folyamat, amelynek során szoftvereket használnak…”
2. Beszélgetési írás
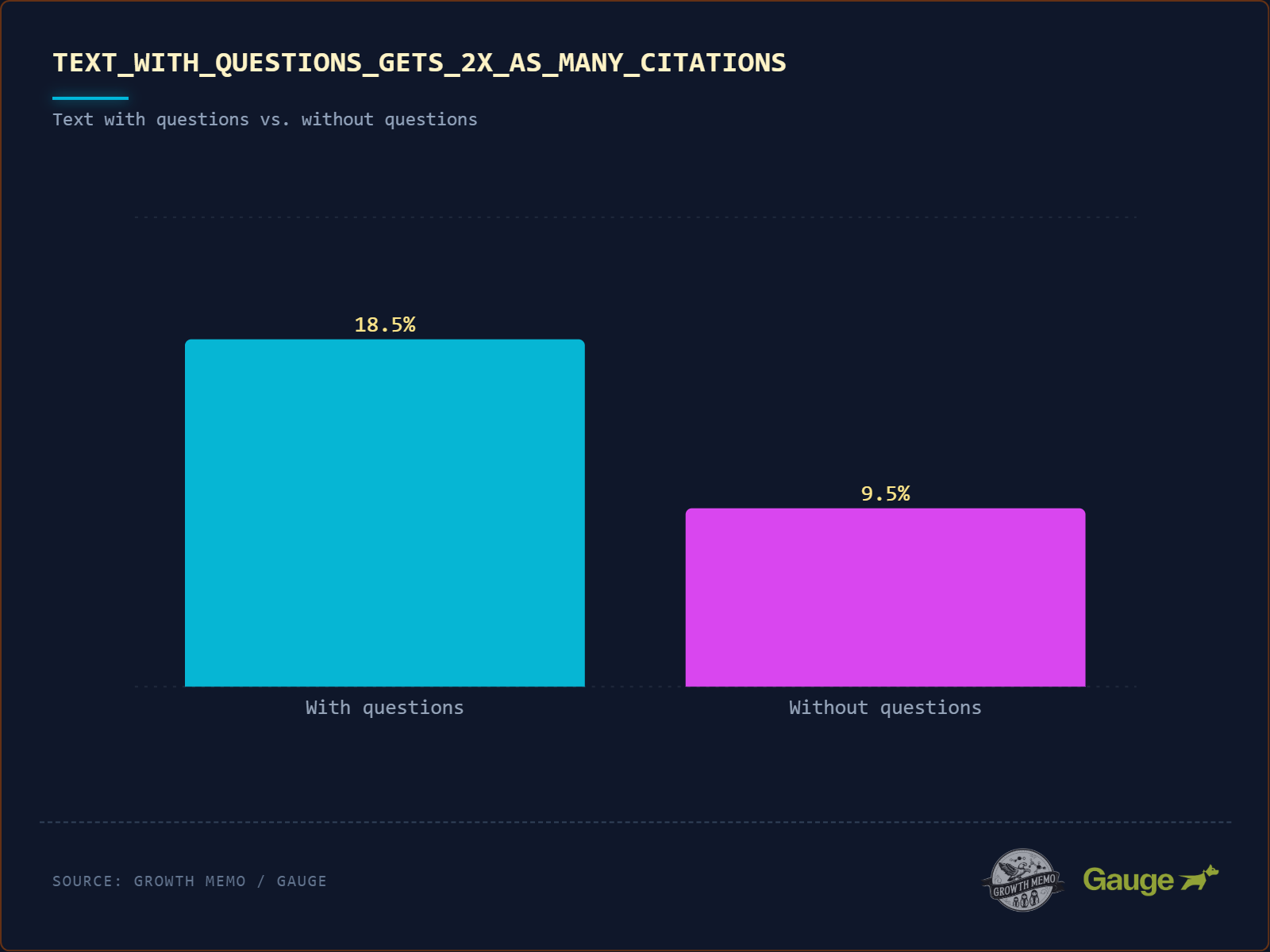
Az idézett szöveg kétszer nagyobb valószínűséggel (18% vs. 8,9%) tartalmaz kérdőjelet. Amikor beszélgetős írásról beszélünk, akkor a kérdések és válaszok kölcsönhatását értjük alatta.
Kezdje kérdésként a felhasználó lekérdezésével, majd azonnal válaszoljon rá. Például:
- Nyertes stílus: „Mi az az automatizált SEO? Ez…”
- Vesztes stílus: „Ebben a cikkben megvitatjuk a…”
A kérdést tartalmazó idézetek 78,4%-a címsorból származik. A mesterséges intelligencia a H2 címkét felhasználói felszólításként, az azt közvetlenül követő bekezdést pedig generált válaszként kezeli.
Példa vesztes szerkezetre:
Példa a nyertes szerkezetére (78%):
-
Mikor indult a SEO?
(Szó szerinti lekérdezés)
-
A SEO kezdete…
(Közvetlen válasz)
Az ok, amiért konkrét példa nyer, az az, amit én „entity echoing”-nak hívok: A fejléc a SEO-ra kérdez rá, és a válasz legelső szava a SEO.
3. Entitásgazdagság
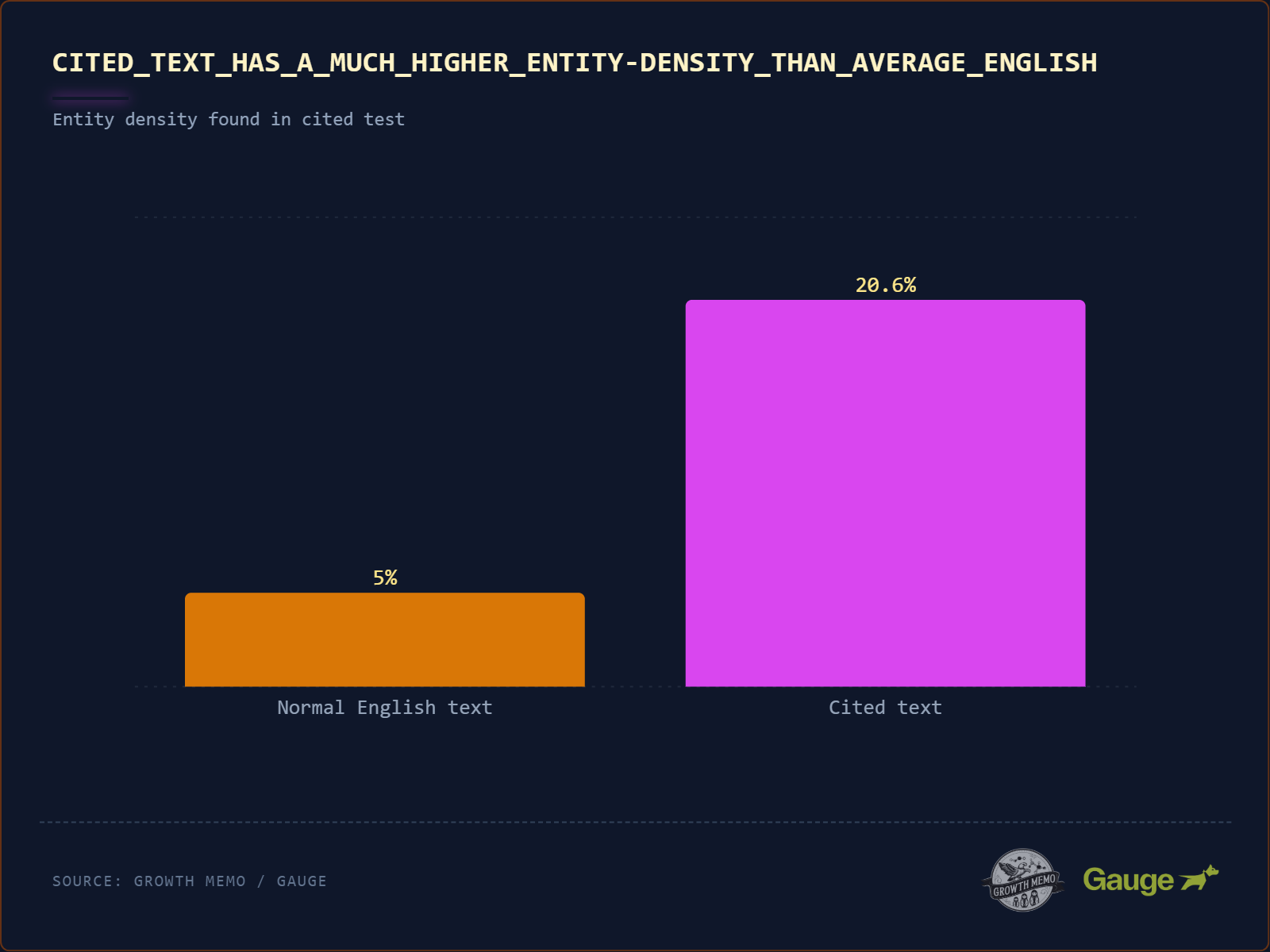
A normál angol szöveg „entity density” (azaz olyan tulajdonneveket tartalmaz, mint a brands, tools, people) ~5-8%. A sokat idézett szövegek entitássűrűsége 20,6%!
- Az 5-8%-os adat egy nyelvi benchmark, amely olyan szabvány korpuszokból származik, mint a Brown Corpus (1 millió szó reprezentatív angol szöveg) és a Penn Treebank (Wall Street Journal szöveg).
Példa:
- Vesztes mondat: „Sok jó eszköz létezik erre a feladatra.” (0% sűrűség)
- Nyertes mondat: „A legnépszerűbb eszközök közé tartozik a Salesforce, a HubSpot és a Pipedrive.” (30%-os sűrűség)
Az LLM-ek valószínűségiek. Az általános tanács („válasszon egy jó eszközt”) kockázatos és homályos, de egy konkrét entitás („válasszon Salesforce-t”) megalapozott és ellenőrizhető. A modell előnyben részesíti azokat a mondatokat, amelyek „horgonyokat” (entitásokat) tartalmaznak, mert csökkentik a válasz zavartságát (zavarosságát).
Egy három entitást tartalmazó mondat több „bit” információt hordoz, mint egy 0 entitást tartalmazó mondat. Tehát ne féljen a névledobástól (igen, még a versenytársaitól sem).
4. Kiegyensúlyozott hangulat
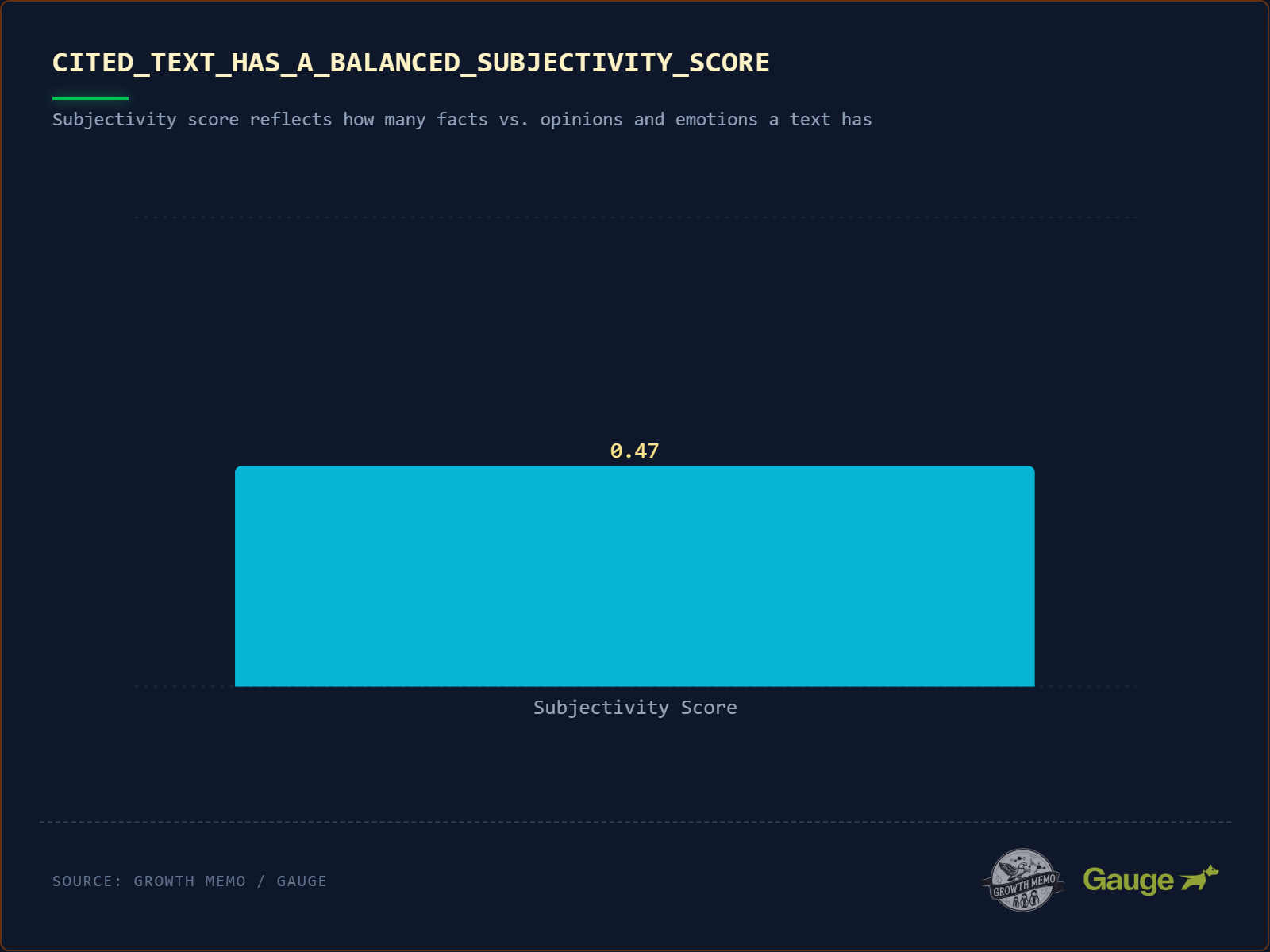
Elemzésemben az idézett szöveg kiegyensúlyozott szubjektivitási pontszáma 0,47. A szubjektivitás pontszáma a természetes nyelvi feldolgozás (NLP) szabványos mérőszáma, amely a személyes vélemény, érzelem vagy ítélet mennyiségét méri egy szövegrészben.
A pontszám egy 0,0-tól 1,0-ig terjedő skálán fut:
- 0,0 (Tiszta tárgyilagosság): A szöveg csak ellenőrizhető tényeket tartalmaz. Nincsenek jelzők, nincsenek érzések. Példa: „Az iPhone 15 2023 szeptemberében jelent meg.”
- 1.0 (Tiszta szubjektivitás): A szöveg csak személyes véleményeket, érzelmeket vagy intenzív leírókat tartalmaz. Példa: „Az iPhone 15 egy teljesen lenyűgöző remekmű, amit szeretek.”
A mesterséges intelligencia nem akar száraz Wikipédia-szöveget (0,1), és nem akar zökkenőmentes véleményt (0,9). Az „analitikus hangot” akarja. Előnyben részesíti a magyarázó mondatokat hogyan tény érvényesül, ahelyett, hogy pusztán a statisztikát közölnénk.
A „nyertes” hang így néz ki (pontszám ~0,5): „Míg az iPhone 15 szabványos A16 chipet tartalmaz (tény), gyenge fényviszonyok melletti fotózáskor nyújtott teljesítménye kiváló választássá teszi a tartalomkészítők számára (elemzés/vélemény).„
5. Üzleti szintű írás
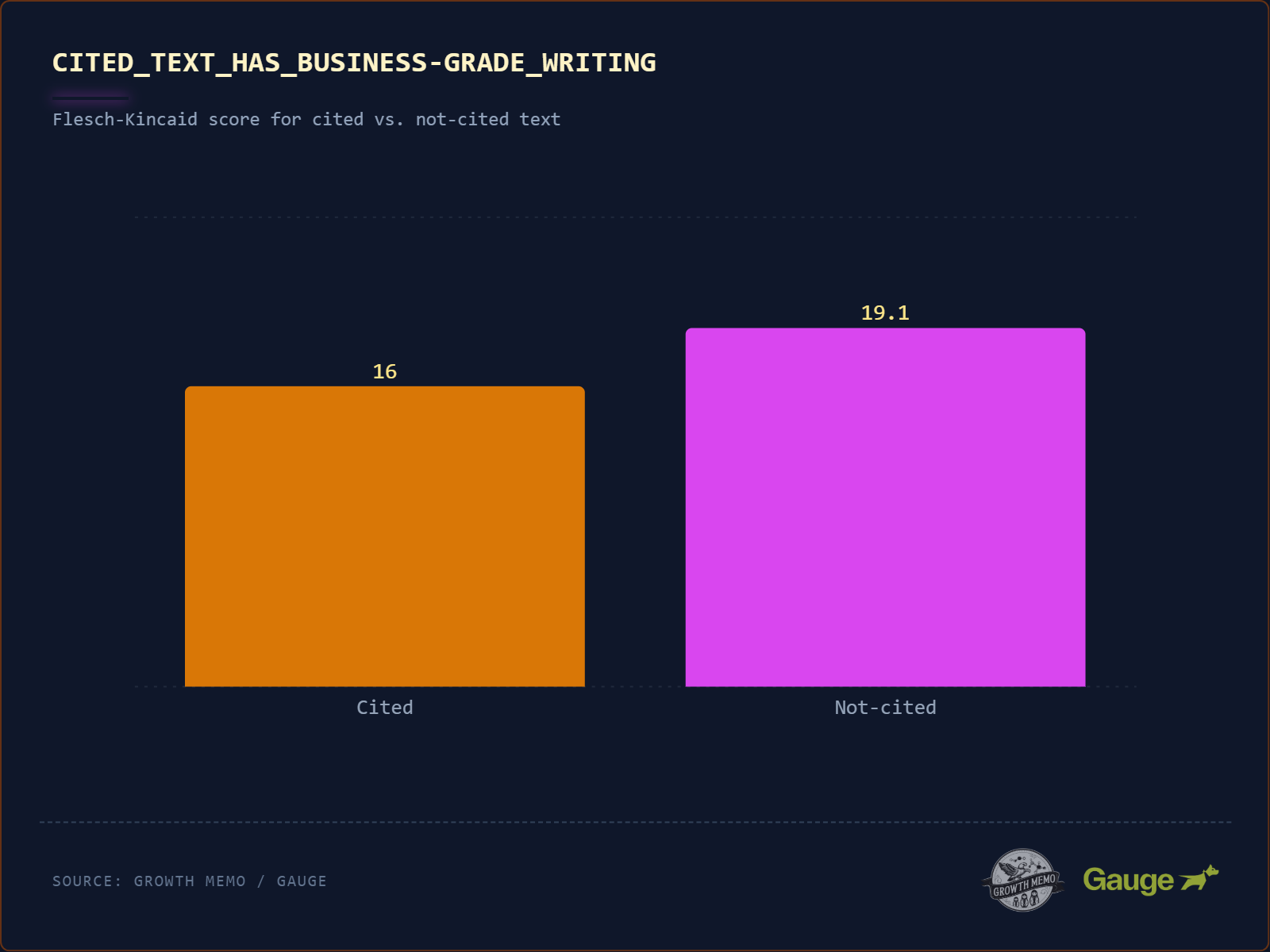
Üzleti szintű írás (gondolj The Economist vagy Harvard Business Review) több idézetet kap. A „győztesek” Flesch-Kincaid pontszáma 16 (főiskolai szint), míg a „vesztesek” 19,1 (akadémiai/PhD szint).
Még összetett témák esetén is árthat a bonyolultság. A 19-es pontszám azt jelenti, hogy a mondatok hosszúak, kanyargósak és tele vannak több szótagos zsargonnal. Az AI az egyszerű alany-ige-tárgy szerkezeteket részesíti előnyben, rövid vagy közepesen hosszú mondatokkal, mert ezekből könnyebb kiszedni a tényeket.
Következtetés
A „sípálya” minta számszerűsíti a narratív írás és az információkeresés közötti eltérést. Az algoritmus a lassú feltárást önbizalomhiányként értelmezi. Előnyben részesíti az entitások és tények azonnali osztályozását.
A jól látható tartalom inkább strukturált eligazításként funkcionál, mint történetként.
Ez „tisztasági adót” ró az íróra. Ebben az adatkészletben a nyertesek az üzleti szintű szókincsre és a nagy entitássűrűségre támaszkodnak, megcáfolva azt az elméletet, amely szerint a mesterséges intelligencia jutalmazza a tartalom „lebutítását” (kivételekkel).
Nem csak robotokat írunk… még. De az emberi preferenciák és a gépi korlátok közötti szakadék bezárul. Az üzleti írás során az emberek betekintést keresnek. A következtetés elölről történő betöltésével kielégítjük az algoritmus architektúráját és az emberi olvasó időhiányát.
Módszertan
Hogy pontosan megértsem ahol és Miért Az AI tartalmat idéz, mi elemeztük a kódot.
A kutatásban szereplő összes adat a Gauge-től származik.
- A Gauge nagyjából 3 millió AI választ adott a ChatGPT-től, 30 millió idézet mellett. Minden hivatkozási URL webtartalmát a válasz idején lekaparták, hogy közvetlen összefüggést biztosítsanak a valódi webtartalom és maga a válasz között. A nyers HTML és a sima szöveg is le lett kaparva.
1. Az adatkészlet
1,2 millió keresési eredményből és mesterséges intelligencia által generált válaszokból álló univerzummal indultunk. Ebből izoláltunk 18 012 ellenőrzött idézetet a helyzetelemzéshez és 11 022 idézetet a „nyelvi DNS” elemzéshez.
- Jelentőség: Ez a mintaméret elég nagy ahhoz, hogy 0,0 P-értéket adjon (p < 0,0001), vagyis az általunk talált minták statisztikailag vitathatatlanok.
2. A „Betakarító” motor
Annak megállapításához, hogy az AI pontosan melyik mondatot idézi, szemantikai beágyazást (neurális hálózat megközelítés) használtunk.
- A modell: Az all-MiniLM-L6-v2-t használtuk, egy mondat-transzformátor modellt, amely megérti a jelentést, nem csak a kulcsszavakat.
- A folyamat: Minden mesterséges intelligencia választ és a forrásszöveg minden mondatát 384 dimenziós vektorokká konvertáltuk. Ezután koszinuszos hasonlóság segítségével párosítottuk őket.
- A szűrő: Szigorú hasonlósági küszöböt (0,55) alkalmaztunk a gyenge egyezések vagy hallucinációk elvetésére, biztosítva, hogy csak a nagy megbízhatóságú idézeteket elemezzük.
3. A mérőszámok
Miután megtaláltuk a pontos egyezést, két dolgot mértünk:
- Pozíciós mélység: Pontosan kiszámítottuk, hogy a hivatkozott szöveg hol jelenik meg a HTML-ben (pl. 10%-nál a 90%-os ponttal szemben).
- Nyelvi DNS: Összehasonlítottuk a „győzteseket” (idézett bevezetők) a „vesztesekkel” (kihagyott bevezetőkkel) a Natural Language Processing (NLP) segítségével, hogy mérjük:
- Meghatározási arány: Végleges igék jelenléte (van, van, utal).
- Entitássűrűség: A tulajdonnevek gyakorisága (márkák, eszközök, emberek).
- Szubjektivitás: 0,0 (tény) és 1,0 (vélemény) közötti hangulati pontszám.
