

Ezt a bejegyzést az Alli AI szponzorálta. A cikkben kifejtett vélemények a szponzor sajátjai.
Mindenki azt feltételezi, hogy a Googlebot a domináns feltérképező robot, amely eléri a webhelyét. Ez a feltételezés most téves.
24 411 048 proxykérést elemeztünk 78 000+ oldalon 69 ügyfélwebhelyen az Alli AI feltérképező robot-engedélyezési platformján 55 napos időszak alatt (2026. januártól márciusig). Az OpenAI ChatGPT-User feltérképező robotja 3,6-szor több kérést küldött, mint a Googlebot az adatmintánkban. És ez nem számít bele a GPTBot-ba, az OpenAI különálló képzési bejárójába.
Megjegyzés a módszertanhoz: A feltérképező robot azonosítása felhasználói ügynök karakterlánc-egyezést használt, a közzétett IP-tartományokhoz képest ellenőrizve. A kérések mérőszámait a proxy/CDN réteg méri. Az adatkészlet 69 webhelyet fed le különféle iparágakban és méretekben, túlnyomórészt WordPress-alapúak. A teljes módszertan a végén található.
1. megállapítás: A mesterséges intelligencia feltérképező robotjai már megelőzik a Google 3.6-szorosát, és a ChatGPT vezeti
Amikor minden azonosított bejárót kérésmennyiség szerint rangsoroltunk, az eredmények egyértelműek voltak:
| Rang | Bejáró | Kérések | Kategória |
| 1 | ChatGPT-Felhasználó (OpenAI) | 133,361 | AI keresés |
| 2 | Googlebot | 37,426 | Hagyományos keresés |
| 3 | Amazonbot | 35,728 | AI / e-kereskedelem |
| 4 | Bingbot | 18.280 | Hagyományos keresés |
| 5 | ClaudeBot (antropikus) | 13 918 | AI keresés |
| 6 | MetaBot | 10 756 | Szociális |
| 7 | GPTBot (OpenAI) | 8,864 | AI képzés |
| 8 | Applebot | 6,794 | AI keresés |
| 9 | Bytespider (ByteDance) | 6,644 | AI képzés |
| 10 | PerplexityBot | 5,731 | AI keresés |
A ChatGPT-User több kérést nyújtott be, mint a Googlebot, az Amazonbot és a Bingbot kombinált.
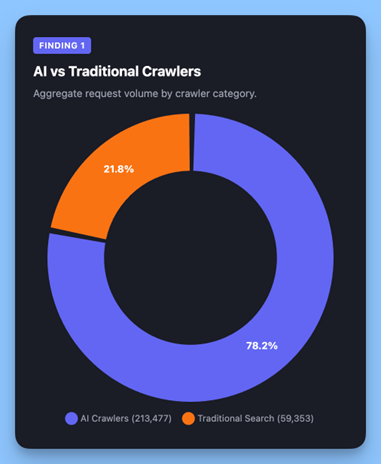
Cél szerint csoportosítva, mesterséges intelligenciával kapcsolatos bejárók (ChatGPT-User, GPTBot, ClaudeBot, Amazonbot, Applebot, Bytespider, PerplexityBot, CCBot) készültek 213 477 kérés kontra 59,353 hagyományos keresőrobotokhoz (Googlebot, Bingbot, YandexBot). A mesterséges intelligenciarobotok mostanra 3,6-szor több kérést intéznek hálózatunkon, mint a hagyományos keresőrobotok.
2. megállapítás: Az OpenAI 2 feltérképező robotot használ (és a legtöbb webhely nem ismeri a különbséget)
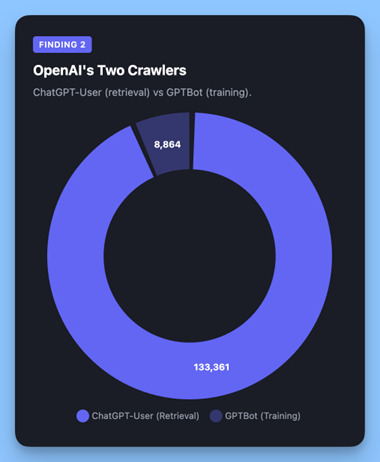
Az OpenAI két különálló bejárót működtet, nagyon eltérő célokkal.
ChatGPT-Felhasználó a visszakereső robot. Valós időben tölti le az oldalakat, amikor a felhasználók olyan ChatGPT-kérdéseket tesznek fel, amelyek naprakész webes információkat igényelnek. Ez határozza meg, hogy az Ön tartalma megjelenik-e a ChatGPT válaszai között.
GPTBot a kiképző bejáró. Adatokat gyűjt az OpenAI modelljeinek fejlesztése érdekében. Sok webhely blokkolja a GPTBot-ot a robots.txt fájlon keresztül, de nem a ChatGPT-User-t, vagy fordítva, anélkül, hogy megértené mindegyik következményeit.
Az OpenAI bejárói együttesen 142 225 kérést tettek: A Googlebot hangerejének 3,8-szorosa.
A robots.txt direktívák különállóak:
User-agent: GPTBot # Training crawler — feeds OpenAI's models
User-agent: ChatGPT-User # Retrieval crawler — fetches pages for ChatGPT answers
3. megállapítás: A mesterséges intelligencia feltérképező robotjai gyorsabbak és megbízhatóbbak, de a mennyiségük nő
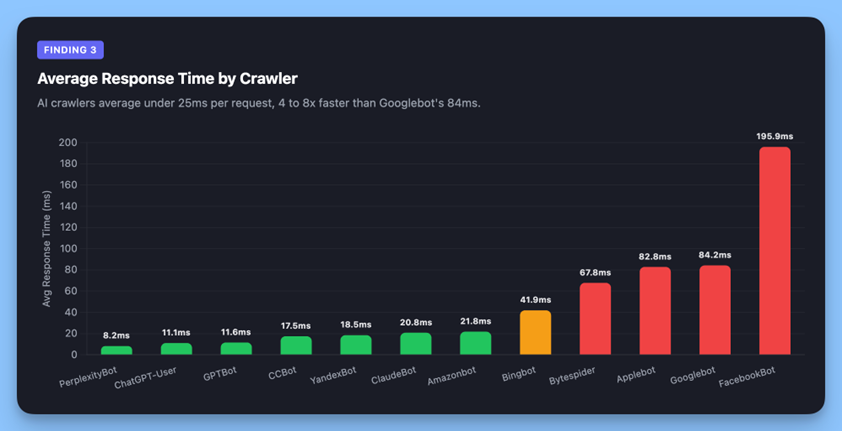
Az AI bejárók kérésenként lényegesen hatékonyabbak:
| Bejáró | Átlagos válaszidő | 200 sikerességi arány |
| PerplexityBot | 8 ms | 100% |
| ChatGPT-Felhasználó | 11 ms | 99,99% |
| GPTBot | 12 ms | 99,9% |
| ClaudeBot | 21 ms | 99,9% |
| Bingbot | 42 ms | 98,4% |
| Googlebot | 84 ms | 96,3% |
Két valószínű ok. Először is, a mesterséges intelligencia lekérő robotjai bizonyos oldalakat kérnek le a felhasználói lekérdezésekre válaszul, nem fedezik fel teljesen a webhely architektúráját. Tudják, mit akarnak, megragadják, és elmennek. Másodszor, míg az infrastruktúránkon lévő összes feltérképező robot előre megjelenített válaszokat kap, a Googlebot szélesebb feltérképezési mintája azt jelenti, hogy az URL-ek szélesebb körét kéri, beleértve a webhelytérképek elavult elérési útjait és a saját örökölt indexét, ami növeli az átirányítási láncokból származó késleltetést és a hibakezelést, amelyet a visszakereső robotok teljesen elkerülnek.
De van egy trükk: bár minden egyes kérés könnyű, a puszta mennyiség azt jelenti, hogy az összesített szerverterhelés jelentős. A ChatGPT-User 11 ms × 133 361 kérés esetén továbbra is valós infrastrukturális költséget jelent, csak másként van elosztva, mint a Googlebot kevesebb, súlyosabb kérése.
4. megállapítás: A Googlebot egy másik (rosszabb) verziót lát a webhelyről
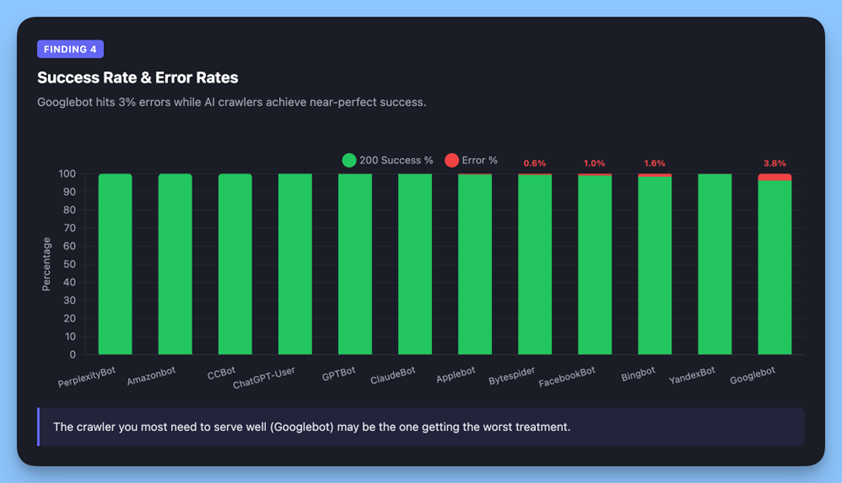
A Googlebot 96,3%-os sikerességi aránya a mesterséges intelligenciarobotok csaknem tökéletes arányához képest fontos szerkezeti különbségről árulkodik.
A Googlebot 624 blokkolt választ (403) és 480 nem talált hibát (404) kapott, ami kérésének 3%-a. Eközben a ChatGPT-User 99,99%-os sikert ért el. A PerplexityBot tökéletes 100%-ot ért el.
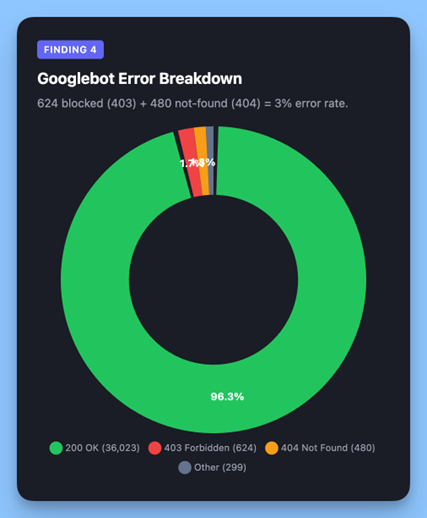
Miért a szakadék? A legvalószínűbb magyarázat az indexelés kora és a feltérképezési viselkedés, nem pedig a webhely hibás beállítása.
A Googlebot hatalmas örökölt indexet tart fenn, amely évek óta tartó folyamatos feltérképezés során épült fel. Rutinszerűen újrakéri azokat az URL-eket, amelyekről már tud – beleértve az azóta törölt (404-es) vagy átstrukturált (403-as) oldalakat is. Ez normális viselkedés egy ilyen léptékű indexet fenntartó keresőmotornál, de ez azt jelenti, hogy a Googlebot kérelmeinek jelentős százaléka olyan URL-ekre irányul, amelyek már nem léteznek.
A mesterséges intelligencia bejárói nem viszik ezt a poggyászt. A ChatGPT-User adott oldalakat kér le a valós idejű felhasználói lekérdezésekre válaszul, és az aktuálisan releváns és hivatkozott tartalmat célozza meg. Ez egy strukturális előny, amely csaknem tökéletes sikerarányt eredményez.
Az iparági jelentések megerősítik, hogy 2025-ben 15-szörösére nőtt a mesterséges intelligencia feltérképezése
Ezek az eredmények összhangban vannak a szélesebb iparági trendekkel. A Cloudflare 2025-ös elemzése szerint a ChatGPT-felhasználók kérelmei éves szinten 2825%-kal nőttek, az AI „felhasználói műveletek” feltérképezése pedig több mint 15-szörösére nőtt 2025 folyamán. Az Akamai az OpenAI-t azonosította a legnagyobb mesterségesintelligencia-bot-üzemeltetőként, amely az összes AI-bot-kérelem 42,4%-át teszi ki. A Vercel a nextjs.org elemzése megerősítette, hogy jelenleg egyik fő mesterséges intelligencia-robot sem jeleníti meg a JavaScriptet.
Adataink azt mutatják, hogy ez a keresztezés már megtörténhet a webhely szintjén azoknál a tulajdonságoknál, amelyek aktívan lehetővé teszik az AI-robot elérését.
Az Ön új SEO-stratégiája: Auditálás, tisztítás és optimalizálás az AI-robotokhoz
1. Vizsgálja meg robots.txt fájlját az AI feltérképező robotokhoz még ma
A legtöbb robots.txt fájl a Googlebot-első világ számára készült. Legalább legyen kifejezett direktívája a ChatGPT-User, GPTBot, ClaudeBot, Amazonbot, PerplexityBot, Applebot, Bytespider, CCBot és Google-Extended számára.
Javaslatunk: A legtöbb vállalkozás számára előnyös mindkét visszakereső robot (ChatGPT-User, PerplexityBot, ClaudeBot) engedélyezése. és betanítási robotok (GPTBot, CCBot, Bytespider), a betanítási adatok azok, amelyek megtanítják ezeket a modelleket a márkáról, termékeiről és szakértelméről. Ha ma blokkolja a feltérképező robotokat, az AI-modellek holnap kevesebbet tudnak meg Önről, ami csökkenti annak esélyét, hogy a mesterséges intelligencia által generált válaszokban hivatkozzanak rájuk.
Kivétel: ha olyan tartalommal rendelkezik, amelyet kifejezetten meg kell védenie a modellképzéstől (védett kutatás, zárt tartalom), használjon granulált Letiltás szabályokat ezekre az útvonalakra, nem pedig általános blokkokra.
2. Tisztítsa meg az elavult URL-eket a Google Search Console-ban
Adataink azt mutatják, hogy a Googlebot 3%-os hibaarányt ér el, többnyire 403-as és 404-es hibaarányt, míg az AI-robotok csaknem tökéletes sikerarányt érnek el. Ez a hiányosság valószínűleg azt tükrözi, hogy a Googlebot újra feltérképezte a már nem létező régi URL-eket. De ezek a sikertelen kérések továbbra is felemésztik a feltérképezési költségkeretet.
Vizsgálja meg a GSC feltérképezési statisztikáit az ismétlődő 404-es és 403-as statisztikában. Állítson be megfelelő átirányításokat az átstrukturált URL-ekhez, és küldjön be frissített webhelytérképeket.
3. Kezelje az AI feltérképező robotok hozzáférhetőségét külön SEO csatornaként
A rangsor a ChatGPT válaszaiban, a Perplexity eredményeiben és Claude válaszaiban külön láthatósági csatornaként jelenik meg. Ha tartalma nem érhető el ezeknek a feltérképező robotoknak, különösen akkor, ha erős JavaScript-keretrendszereket futtat, akkor láthatatlan az AI-keresésben.
Megjelent a élő műszerfal megmutatja, hogyan oszlik meg a mesterséges intelligenciarobot forgalom egy valós webhelyen: mely platformokat látogatják, milyen gyakran, és ezek részesedése a teljes forgalomból; ha látni szeretnéd, hogy néz ki ez a gyakorlatban.
4. Tervezze a mennyiséget, ne csak az egyéni kérés súlyát
Az AI-robotok könnyű, gyors kéréseket küldenek, de küldenek sok közülük. Csak a ChatGPT-User több mint 133 000 kérést adott 55 nap alatt. Az AI-robotok összesített szerverterhelése valószínűleg meghaladja a Googlebot-terhelést. Győződjön meg róla, hogy a tárhely és a CDN kezelni tudja, az adataink alacsony kérésenkénti válaszideje azt a tényt tükrözi, hogy az Alli AI előre renderelt statikus HTML-t szolgál ki a CDN éléről, ami pontosan az a fajta architektúra, amely elnyeli ezt a kötetet anélkül, hogy megadóztatná az eredeti szervert.
Módszertan
Ez az elemzés 2026. január 14. és március 9. között az Alli AI bejáró engedélyezési platformján keresztül feldolgozott 24 411 048 HTTP-proxy kérelmen alapul, amelyek 69 ügyfélwebhelyet fednek le.
A feltérképező robot azonosítása felhasználói ügynök karakterlánc-egyezést használt, a közzétett IP-tartományokhoz képest ellenőrizve. Kifejezetten az OpenAI bejárók esetében minden kérés kereszthivatkozást kapott az OpenAI közzétett CIDR-tartományaira. Ez megerősítette a GPTBot kérések 100%-át és a ChatGPT-User kérések 99,76%-át az OpenAI infrastruktúrájából. A fennmaradó 0,24% (hamisított felhasználói ügynökök kérései) kizárásra került.
Korlátozások: Az adatkészlet az Alli AI-ügyfelekre vonatkozik, akik engedélyezték a bejáró engedélyezését. Azokat a bejárókat, amelyek nem azonosítják magukat felhasználói ügynökön keresztül, a rendszer nem rögzíti. A válaszidő mérése a proxy rétegben történik, nem a kiindulási kiszolgálón.
Az Alli AI-ról
Az Alli AI szerveroldali renderelési infrastruktúrát biztosít a mesterséges intelligencia és a keresőmotorok bejárói számára. Ezt az elemzést proxy-infrastruktúránk adatainak felhasználásával készítettük, hogy segítsünk a keresőoptimalizálási közösségnek jobban megérteni a fejlődő feltérképező környezetet.
Szeretné látni ezeket az adatokat működés közben? Tekintse meg a bontást első kézből az AI láthatósági irányítópultján.
In-post képek: Alli AI képek. Engedéllyel használt.
