

A Google közzétette az új típusú AI részleteit, amelyek grafikon alapítási modellnek (GFM) nevezik grafikonok alapján, amelyek általánosítják a korábban nem láthatatlan grafikonokat, és három -negyvenszer növelik a Precision -t a korábbi módszerekhez képest, sikeres teszteléssel a skálázott alkalmazásokban, például a spam -észlelésben az ADS -ben.
Ennek az új technológiának a bejelentését úgy nevezik, hogy kibővíti a mai napig terjedő határait:
„Ma feltárjuk annak lehetőségét, hogy egyetlen modellt tervezzünk, amely kiemelkedhet az összekapcsolt relációs táblákon, és ugyanakkor általánosíthat minden tetszőleges táblázatot, funkciót és feladatot kiegészítő képzés nélkül. Örülünk, hogy megoszthatjuk a közelmúltbeli előrelépésünket az ilyen grafikus alapok (GFM) kidolgozásában.”
Grafikon neurális hálózatok Vs. Graph Foundation Models
A grafikonok az egymással kapcsolatos adatok ábrázolása. Az objektumok közötti kapcsolatokat éleknek nevezzük, és magukat az objektumokat csomópontoknak nevezzük. A SEO -ban a legismertebb grafikon típusa azt lehet mondani, hogy a link grafikon, amely a teljes web térképe a linkek szerint, amelyek az egyik weboldalt csatlakoztatják a másikhoz.
A jelenlegi technológia a Graph Neural Networks -t (GNNS) használja az olyan adatok ábrázolására, mint a weboldal tartalma, és felhasználható a weboldal témájának azonosítására.
A GNNS -ről szóló Google Research Blogbejegyzés magyarázza azok fontosságát:
„A grafikonhálózatok vagy a GNN -ek röviden, hatékony technikává váltak mind a grafikon összekapcsolhatóságának kiaknázására (mint a régebbi algoritmusokban a Deepwalk és a Node2Vec), és a bemeneti funkciók a különféle csomópontokon és éleknél. A GNN -ek előrejelzéseket tudnak készíteni a grafikonok számára (ez a dokumentumok egy bizonyos módon?
Amellett, hogy előrejelzéseket készít a grafikonokról, a GNN -k egy hatékony eszköz, amely a szakadék áthidalására szolgál a tipikusabb neurális hálózati felhasználási esetekre. Folyamatosan kódolják a gráf diszkrét, relációs információit, hogy természetesen beépíthessék egy másik mély tanulási rendszerbe. ”
A GNN -k hátránya, hogy azok a grafikonhoz vannak kötve, amelyen képezték őket, és nem használhatók másfajta grafikonon. Egy másik grafikonon történő használatához a Google -nak egy másik modellt kell kiképeznie, kifejezetten az adott grafikonhoz.
Analógia elkészítéséhez olyan, mintha egy új generatív AI modellt kellene kiképeznie a francia nyelvű dokumentumokra, csak azért, hogy egy másik nyelven működjön, de nem ez a helyzet, mert az LLMS általánosíthat más nyelvekre, ami nem ez a helyzet a grafikonokkal működő modellek esetében. Ez a probléma megoldja a találmányt, hogy létrehozzon egy olyan modellt, amely általánosítja a többi grafikonot anélkül, hogy előbb képzést kellene képezni.
Az áttörés, amelyet a Google bejelentett, az, hogy az új Graph Foundation Models -rel a Google most olyan modellt képezhet, amely általánosíthat olyan új grafikonokat, amelyekre nem képzett, és megértik a mintákat és a kapcsolatokat ezen grafikonokon belül. És pontosabban meg tudja csinálni három -negyvenszer.
Bejelentés, de nincs kutatási cikk
A Google bejelentése nem kapcsolódik egy kutatási cikkhez. Különbözően beszámoltak arról, hogy a Google úgy döntött, hogy kevesebb kutatási dokumentumot tesz közzé, és ez a politikai változás nagy példája. Azért van, mert ez az innováció olyan nagy, hogy ezt versenyelőnynek akarják tartani?
Hogyan működnek a Graph Foundation Models
Tegyük fel a hagyományos grafikonon, mondjuk az internet grafikonját, a weboldalak a csomópontok. A csomópontok (weboldalak) közötti linkeket éleknek nevezzük. Az ilyen típusú grafikonban hasonlóságokat láthat az oldalak között, mivel az adott téma oldalai általában más oldalakhoz kapcsolódnak, ugyanazon a témáról.
Nagyon egyszerű értelemben a Graph Foundation modell minden táblázat minden sorát csomóponttá alakítja, és a táblázatok kapcsolatok alapján összeköti a kapcsolódó csomópontokat. Az eredmény egyetlen nagy grafikon, amelyet a modell a meglévő adatokból való tanulásra és az új adatokra vonatkozó előrejelzések (például a spam azonosítása) felhasználására használ.
Öt asztal képernyőképe
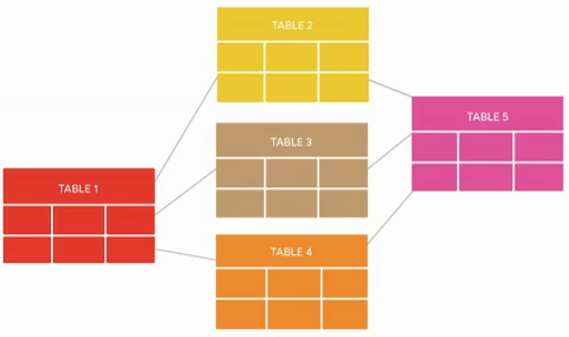
A táblák átalakítása egyetlen grafikonra
A kutatási cikk ezt mondja a következő képekről, amelyek szemléltetik a folyamatot:
„Az adatok előkészítése a táblák egyetlen grafikonra történő átalakításából áll, ahol a táblázat minden sora a megfelelő csomópont típusú csomóponttá válik, és az idegen kulcsoszlopok szélei lesznek a csomópontok között. A bemutatott öt táblázat közötti csatlakozás szélekké válnak a kapott grafikonon.”
A szélekre konvertált táblák képernyőképe
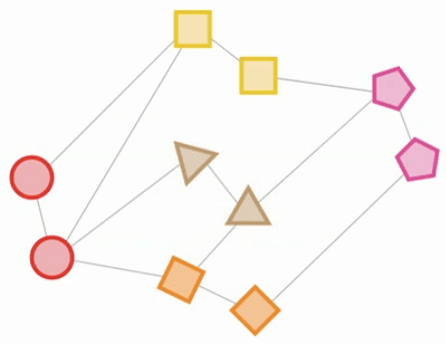
Az új modell kivételessé teszi az, hogy a létrehozásának folyamata „egyértelmű”, és ez skálán van. A méretezésről szóló rész fontos, mert azt jelenti, hogy a találmány képes működni a Google hatalmas infrastruktúráján.
„Azt állítjuk, hogy a táblázatok közötti csatlakozási struktúra kihasználása kulcsfontosságú a hatékony ML algoritmusokhoz és a jobb downstream teljesítményhez, még akkor is, ha a táblázatos funkciók (pl. Ár, méret, kategória) ritka vagy zajos. E célból az egyetlen adatkészítési lépés a táblák gyűjteményének egyetlen heterogén grafikonra történő átalakításából áll.
A folyamat meglehetősen egyértelmű és méretarányon végrehajtható: minden táblázat egyedi csomóponttípussá válik, és a táblázat minden sora csomóponttá válik. A táblázat minden sorához külföldi kulcstartásai tipizált szélekké válnak a megfelelő csomópontokhoz a többi táblából, míg a többi oszlopot csomópontjellemzőkként kezelik (általában numerikus vagy kategorikus értékekkel). Opcionálisan az időbeli információkat csomópont vagy él funkcióként is megtarthatjuk. ”
A tesztek sikeresek
A Google bejelentése azt mondja, hogy tesztelték a spam azonosításában a Google hirdetésekben, ami nehéz volt, mert ez egy olyan rendszer, amely tucatnyi nagy grafikont használ. A jelenlegi rendszerek nem képesek kapcsolatot létesíteni a független grafikonok és a fontos kontextus hiánya között.
A Google új Graph Foundation modellje képes volt kapcsolatba lépni az összes grafikon és a jobb teljesítmény között.
A bejelentés leírta az eredményt:
„Figyelembe vesszük a jelentős teljesítménynövekedést a legjobban hangolt egyszemélyes alapvonalakhoz képest. A downstream feladattól függően a GFM átlagos pontosságban 3x-40x nyereséget eredményez, ami azt jelzi, hogy a relációs táblázatok gráfszerkezete kritikus jelet ad, amelyet az ML modellek kihasználnak.”
A Google használja ezt a rendszert?
Figyelemre méltó, hogy a Google sikeresen tesztelte a rendszert a Google hirdetéseivel a spam -észleléshez, és bejelentette az oldalakat, és nincs hátránya. Ez azt jelenti, hogy élő környezetben használható különféle valós feladatokhoz. Használták a Google ADS spam -észlelésére, és mivel ez egy rugalmas modell, ami azt jelenti, hogy más olyan feladatokhoz is felhasználható, amelyekhez több grafikont használnak, a tartalmi témák azonosításától a link spam azonosításáig.
Általában, amikor valami elmarad, a kutatási dokumentumok és a bejelentés azt mondja, hogy ez a jövő útjára mutat, de nem így mutatják be ezt az új találmányt. Sikerként mutatják be, és egy kijelentéssel ér véget, hogy ezek az eredmények tovább javíthatók, azaz még jobb lehet, mint a már látványos eredmények.
„Ezeket az eredményeket tovább lehet javítani a további méretezéssel és a sokszínű képzési adatgyűjtéssel, valamint az általánosítás mélyebb elméleti megértésével.”
Olvassa el a Google bejelentését:
Grafikon alapítási modellek a relációs adatokhoz
