

Amikor a beszélgetési AI -k, mint például a chatgpt, a zavarás vagy a Google AI mód, kivonatot vagy válaszadási összefoglalókat generálnak, akkor nem a semmiből írnak, hanem válogatnak, tömörítenek és újracsomagolják a weboldalakat. Ha a tartalma nem SEO-barát és indexelhető, akkor ez egyáltalán nem teszi a generatív keresésbe. A keresés, amint tudjuk, most a mesterséges intelligencia függvénye.
De mi van, ha az oldal nem „felajánlja” magát géppel olvasható formában? Itt jönnek be a strukturált adatok, nem csak SEO koncertként, hanem az AI állványaként, hogy megbízhatóan válasszák a „helyes tényeket”. Volt némi zavar a közösségünkben, és ebben a cikkben:
- sétáljon át a 97 weboldal ellenőrzött kísérletein, amelyek megmutatják, hogy a strukturált adatok hogyan javítják a részletek konzisztenciáját és a kontextuális relevanciát,
- Térolja ezeket az eredményeket a szemantikai keretünkbe.
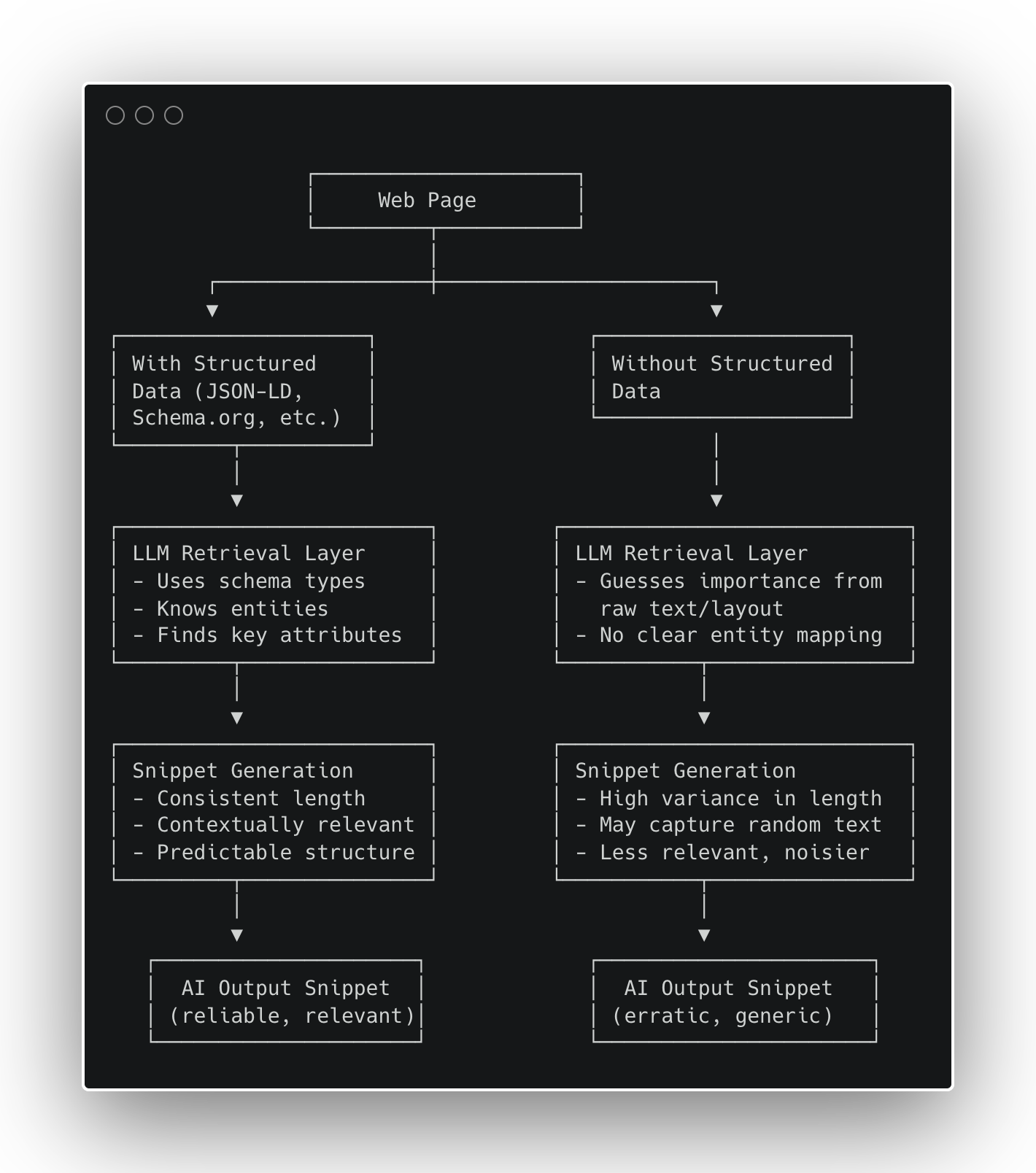
Sokan az elmúlt hónapokban megkérdezték tőlem, hogy az LLM -ek strukturált adatokat használnak -e, és újra és újra megismételtem, hogy az LLM nem használ strukturált adatokat, mivel nincs közvetlen hozzáférése a világhálóhoz. Az LLM eszközöket használ az internet kereséséhez és a weboldalak letöltéséhez. Eszközei – a legtöbb esetben – nagyban részesülnek a strukturált adatok indexelésében.
Korai eredményeinkben a strukturált adatok növelik a részletek konzisztenciáját és javítják a kontextuális relevanciát a GPT-5-ben. Arra is utal, hogy meghosszabbítja a hatékonyságot szóköz Boríték-Ez egy rejtett GPT-5 irányelv, amely eldönti, hogy hány szót kap a tartalma. Képzelje el, hogy ez egy kvóta az AI láthatóságáról, amely kibővül, ha a tartalom gazdagabb és jobban típusa. További információ erről a koncepcióról, amelyet először a LinkedIn -en vázoltam.
Miért számít ez most?
- WordLim korlátozások: Az AI -halmok szigorú token/karakter költségvetéssel működnek. A kétértelműség -hulladékok költségvetése; A gépelt tények megőrzik.
- Egyértelmű és földelés: A schema.org csökkenti a modell keresési területét („Ez egy recept/termék/cikk”), a kiválasztás biztonságosabbá tételével.
- Tudásdiagramok (kg): A séma gyakran táplálja a KG -ket, amelyeket az AI rendszerek konzultálnak a tények beszerzése során. Ez a híd a weblapoktól az ügynökök érveléséig.
Személyes tézisem az, hogy a strukturált adatokat az AI oktatási rétegének akarjuk kezelni. Nem „Rangot neked”, Stabilizálja azt, amit az AI mondhat rólad.
Kísérleti tervezés (97 URL)
Miközben a minta mérete kicsi volt, meg akartam látni, hogy a Chatgpt visszakeresési rétege valóban működik, ha a saját felületéről, nem pedig az API -n keresztül használják. Ehhez kértem a GPT-5-et, hogy keressen és nyisson egy sor URL-t a különféle webhelyekről, és adja vissza a nyers válaszokat.
A GPT-5 (vagy bármely AI rendszer) felszólíthatja a belső szerszámok szó szerinti kimenetét egy egyszerű meta-proppt segítségével. Miután összegyűjtöttem mind az egyes URL -ek keresését, és reagáltak a válaszokat, futtattam egy ügynök WordLift munkafolyamatot [disclaimer, our AI SEO Agent] Minden oldal elemzéséhez ellenőrizze, hogy tartalmaz -e strukturált adatokat, és ha igen, akkor az észlelt specifikus sémakípusok azonosítása.
Ez a két lépés 97 URL -ből származó adatkészletet készített, amely a kulcs mezőkkel megjegyezte:
- HAS_SD → Igaz/hamis zászló a strukturált adatok jelenlétéhez.
- Schema_classes → Az észlelt típus (pl. Recept, termék, cikk).
- Search_raw → A „keresési stílusú” részlet, amely ábrázolja az AI keresési eszközt.
- Open_raw → A GPT-5 oldalán az oldal szerkezeti összefoglalója vagy az oldal szerkezeti soványa.
A Gemini 2.5 Pro által üzemeltetett „LLM-As-A-A-As-A-As-A-As-A-As-As-As-A-As-As-As-A-As-As-As-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-A-Budge” megközelítés három fő mutatójának kinyerésére:
- Következetesség: A search_raw részletek eloszlása (box -diagram).
- Kontextuális relevancia: Kulcsszó és mező lefedettsége az Open_raw oldalon, oldaltípus szerint (recept, e-comm, cikk).
- Minőségi pontszám: Konzervatív 0–1 index, amely kombinálja a kulcsszó jelenlétét, az alapvető NER-jelzéseket (az e-kereskedelemhez) és a séma visszhangja a keresési kimenetben.
A rejtett kvóta: kicsomagolás “szóköz„
Ezeknek a teszteknek a futtatása közben észrevettem egy újabb finom mintát, amely megmagyarázhatja, hogy a strukturált adatok miért vezetnek következetesebb és teljes részletekhez. A GPT-5 visszakeresési csővezetékén belül van egy belső irányelv, amelyet informálisan WordLim néven ismertek: egy dinamikus kvóta, amely meghatározza, hogy az egyetlen weboldalból származó szöveget mekkora szöveget eredményezhet egy generált válasz.
Első pillantásra egy szóhatárként működik, de adaptív. Minél gazdagabb és jobban típusa az oldal tartalma, annál több helyet szerez a modell szintézis ablakában.
A folyamatban lévő megfigyeléseimből:
- Strukturálatlan tartalom (pl. Egy standard blogbejegyzés) hajlamos kb. 200 szót kapni.
- Strukturált tartalom (pl. A termékjelölés, a takarmányok) ~ 500 szóra terjed ki.
- Sűrű, hiteles források (API -k, kutatási dokumentumok) több mint 1000 szót érhetnek el.
Ez nem önkényes. A limit segíti az AI rendszereket:
- Ösztönözze a szintézist a forrásokon belüli szintézist, nem pedig a másolat-tételt.
- Kerülje a szerzői jogi kérdéseket.
- Tartsa a válaszokat tömören és olvashatónak.
Ugyanakkor bevezet egy új SEO határot is: a strukturált adatok hatékonyan növelik a láthatóság kvótáját. Ha az adatait nem strukturálták, akkor a minimumot korlátozják; Ha igen, akkor több bizalmat és több helyet biztosít az AI -nek a márkájának megjelenítéséhez.
Noha az adatkészlet még nem elég nagy ahhoz, hogy statisztikailag szignifikáns legyen minden függőleges területen, a korai minták már egyértelműek – és cselekvőképesek.
Eredmény
1) Konzisztencia: A részletek kiszámíthatók a sémával
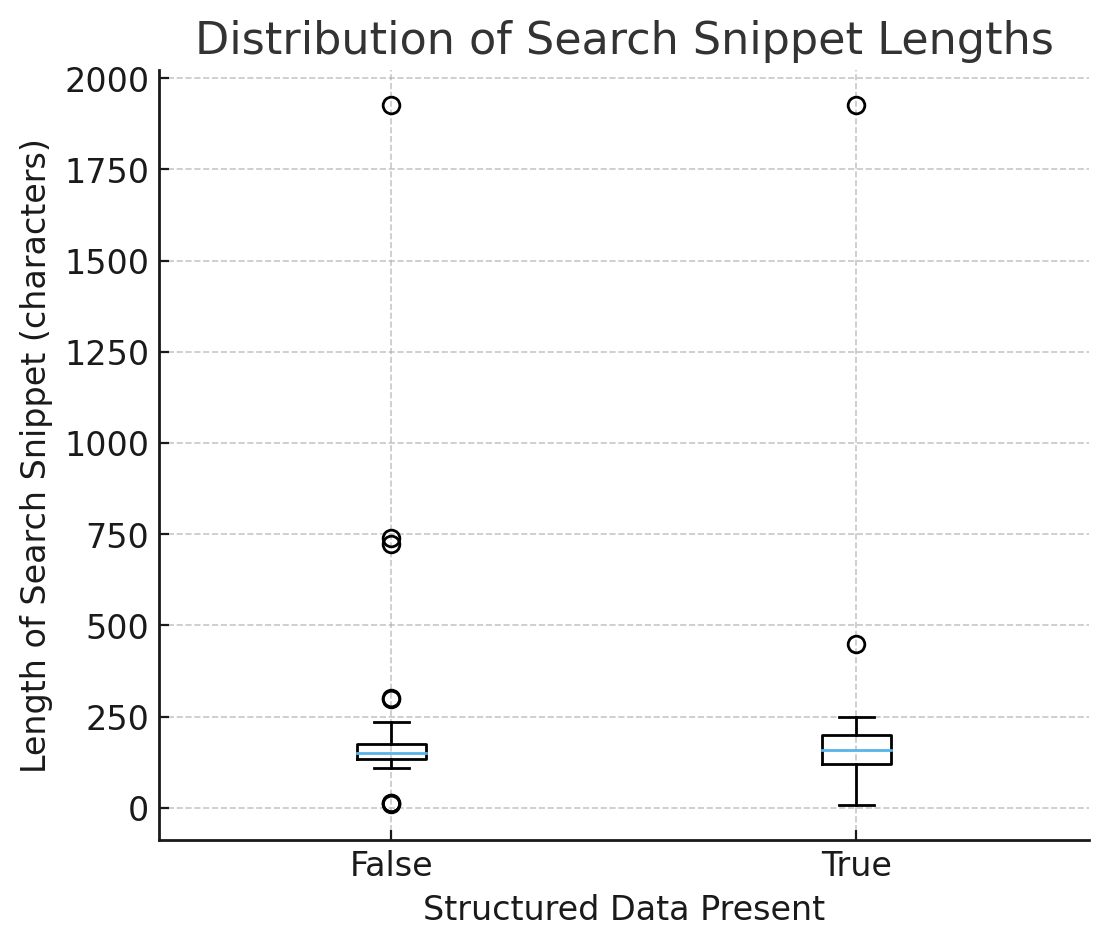
A keresési részletek hosszúságának dobozában (vs. strukturált adatok nélkül):
- A mediánok hasonlóak.
- A terjedés (IQR és pofaszakáll) szűkebb, amikor has_sd = true → Kevésbé szokatlan kimenet, kiszámíthatóbb összefoglalók.
Értelmezés: A strukturált adatok nem növelik a hosszát; Csökkenti a bizonytalanságot. A modellek alapértelmezetten a gépelt, biztonságos tényekhez, ahelyett, hogy az önkényes HTML -ből kitalálnák.
2) Kontextuális relevancia: séma vezetők kinyerése
- Receptek: Vel Recept A séma, a letöltési összefoglalók sokkal valószínűbb, hogy tartalmazzák az összetevőket és a lépéseket. Tiszta, mérhető emelés.
- E -kereskedelem: A keresőeszköz gyakran visszhangozza a JSON -LD mezőket (pl. összevonó, ajánlat, márka) Bizonyíték arra, hogy a sémát olvasják és felszínre kerülnek. Az összefoglalók letöltése a pontos terméknevekhez ferde olyan általános kifejezések felett, mint az „ár”, de az identitás rögzítése erősebb a sémával.
- Cikkek: Kicsi, de jelenlegi nyereség (a szerző/dátum/címsor nagyobb valószínűséggel jelenik meg).
3) Minőségi pontszám (minden oldal)
A 0–1 pontszám átlagolása az összes oldalon:
- Nincs séma → ~ 0,00
- Sémával → A pozitív felemelkedés, amelyet elsősorban receptek és néhány cikk vezérel.
Még ha hasonlóan is hasonlónak tűnik, a variancia összeomlik a sémával. Egy AI világban, amelyet korlátozott szóköz és a visszakeresési költségek, az alacsony szórás versenyelőny.
Konzisztencián túl: A gazdagabb adatok kiterjesztik a WordLim borítékot (korai jel)
Noha az adatkészlet még nem elég nagy a szignifikancia tesztekhez, megfigyeltük ezt a kialakulóban lévő mintát:
A gazdagabb, többszentségű strukturált adatokkal rendelkező oldalak kissé hosszabb ideig tartanak, sűrűbb részletek a csonka előtt.
Hipotézis: gépelt, összekapcsolt tények (pl. Termék + ajánlat + márka + aggregálódó vagy cikk + szerző + date publikált) Segítsen a modelleknek a magasabb értékű információk prioritása és tömörítése – hatékonyan kibővítve az oldal használható token költségvetését.
A séma nélküli oldalak gyakrabban korai csonkítást kapnak, valószínűleg a relevancia bizonytalansága miatt.
Következő lépés: Megmérjük a szemantikai gazdagság (a különálló séma entitások/attribútumok száma) és a tényleges részletek közötti kapcsolatot. Ha megerősítik, a strukturált adatok nemcsak a részleteket stabilizálják, hanem az információs áteresztőképességet állandó szókorlátozások mellett.
A sémától a stratégiáig: a playbook
A webhelyeket felépítjük:
- Entitás grafikon (Schema/GS1/Cikkek/…): Termékek, ajánlatok, kategóriák, kompatibilitás, helyek, politikák;
- Lexikus grafikon: Kapott másolat (ápolási utasítások, méretvezető, GYIK), amely az entitásokhoz kapcsolódik.
Miért működik: Az entitásréteg biztonságos állványt ad az AI -nek; A lexikai réteg újrafelhasználható, idézhető bizonyítékokat szolgáltat. Együtt vezetik a pontosságot aszóköz korlátozások.
Így fordítjuk ezeket az eredményeket egy megismételhető SEO playbook -ba az AI Discovery korlátozások alatt dolgozó márkák számára.
- Hajó JSON -LD az alapsablonokhoz
- Receptek → Recept (összetevők, utasítások, hozamok, idők).
- Termékek → Termék + ajánlat (Márka, GTIN/SKU, ár, elérhetőség, besorolások).
- Cikkek → Cikk/hírcsatorna (címsor, szerző, date publikált).
- Unify entitás + lexical
Tartsa a specifikációkat, a GYIK -t és a házirend -szöveget, és az entitáshoz kapcsolódik. - Megkeményítve a részletfelületet
A tényeknek következetesnek kell lenniük a látható HTML és a JSON -LD között; Tartsa a kritikus tényeket a hajtás felett és stabil. - Eszköz
A nyomon követési variancia, nem csak az átlagok. Benchmark kulcsszó/mező lefedettsége a gépi összefoglalók sablononként.
Következtetés
A strukturált adatok nem változtatják meg az AI kivonatok átlagos méretét; Megváltoztatja az őket bizonyosság– Stabilizálja az összefoglalókat és kialakítja azt, amit magában foglalnak. A GPT-5-ben, különösen agresszív alatt szóköz A feltételek, hogy a megbízhatóság magasabb minőségű válaszokat, kevesebb hallucinációt és nagyobb márka láthatóságot eredményez az AI által generált eredményeknél.
A SEO -k és a termékcsoportok esetében az elvitel egyértelmű: a strukturált adatokat alapvető infrastruktúrának tekinti. Ha a sablonjainak még mindig hiányzik a szilárd HTML szemantika, Ne ugorj egyenesen a JSON-LD-re: Először javítsa ki az alapokat. Kezdje a jelölés megtisztításával, majd rétegezze a strukturált adatokat a tetejére a szemantikai pontosság és a hosszú távú felfedezés felépítése érdekében. Az AI keresés során a szemantika az új felület.
