

Sokat kell tudni a keresési szándékról, a mély tanulás használatától a keresési szándék következtetéséig a szöveg osztályozásával és a SERP címek bontásával a természetes nyelvfeldolgozási (NLP) technikákkal, a szemantikai relevancia alapján történő klaszterezésig, a magyarázott előnyökkel.
Nem csak tudjuk a keresési szándék megfejtésének előnyeit, hanem számos technikánk is van a skála és az automatizáláshoz.
Szóval, miért van szükségünk egy másik cikkre a keresési szándék automatizálásáról?
A keresési szándék egyre fontosabb most, amikor megérkezett az AI -keresés.
Noha több volt a 10 Blue Links Search korszakban, az ellenkezője igaz az AI keresési technológiával, mivel ezek a platformok általában arra törekszenek, hogy minimalizálják a számítási költségeket (floponként) a szolgáltatás nyújtása érdekében.
A SERP -k továbbra is tartalmazzák a legjobb betekintést a keresési szándékhoz
Az eddigi technikák magukban foglalják a saját AI elvégzését, azaz az összes példány megszerzését a rangsorolási tartalom címeiből egy adott kulcsszó számára, majd egy neurális hálózati modellbe (amelyet majd fel kell építeni és tesztelnie), vagy az NLP használatával a kulcsszavakhoz.
Mi van, ha nincs ideje vagy ismerete a saját AI -jének felépítéséhez, vagy a nyitott AI API -ra való hivatkozáshoz?
Míg a koszinusz hasonlóságot úgy nevezték el, hogy a SEO -szakemberek segítséget nyújtanak a taxonómiai és a helyszíni struktúrák témáinak körülhatárolásában, továbbra is fenntartom, hogy a SERP eredmények általi keresési klaszterezés jóval jobb módszer.
Ennek oka az, hogy az AI nagyon szívesen megalapozza eredményeit a SERP -kre, és jó okból – a felhasználói viselkedésre modellezve.
Van egy másik módja annak, hogy a Google saját AI -jét használja az Ön számára a munka elvégzéséhez, anélkül, hogy az összes SERP tartalmat lekaparná és AI modellt készítenie kellene.
Tegyük fel, hogy a Google a webhely URL -jeit rangsorolja annak valószínűségével, hogy a tartalom csökkenő sorrendben kielégíti a felhasználói lekérdezést. Ebből következik, hogy ha a két kulcsszó szándéka megegyezik, akkor a SERP -k valószínűleg hasonlóak lesznek.
Számos SEO szakember évek óta összehasonlította a SERP eredményeit a kulcsszavakkal a megosztott (vagy megosztott) keresési szándékkal, hogy az alapvető frissítések tetején maradjon, tehát ez nem új.
Az ADUES-Add itt az összehasonlítás automatizálása és méretezése, amely mind a sebességet, mind a nagyobb pontosságot kínálja.
Hogyan kell a kulcsszavakat a Python (kóddal) használatával keresni a kulcsszavakkal.
Feltételezve, hogy a SERPS eredményei CSV -letöltésben vannak, importáljuk a Python notebookba.
1. Importálja a listát a Python notebookba
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
Az alábbiakban bemutatjuk a SERPS fájlt, amelyet most egy Pandas DataFrame -be importálnak.
2. Szűrje az adatokat az 1. oldalra
Szeretnénk összehasonlítani az egyes SERP -k 1. oldalának eredményeit a kulcsszavak között.
Az adatkeretet a Mini kulcsszó -adatkeretekre osztjuk, hogy a szűrési funkciót egyetlen adatkeretre rekombináljuk, mert a kulcsszó szintjén szűrni akarunk:
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] <= k_urls]
return filtered_df
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
# Combine
## Add prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with initial data frame
filtered_serps_df = pd.concat([filtered_serps],axis=0)
del filtered_serps_df['keyword']
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df['level_1']
filtered_serps_df
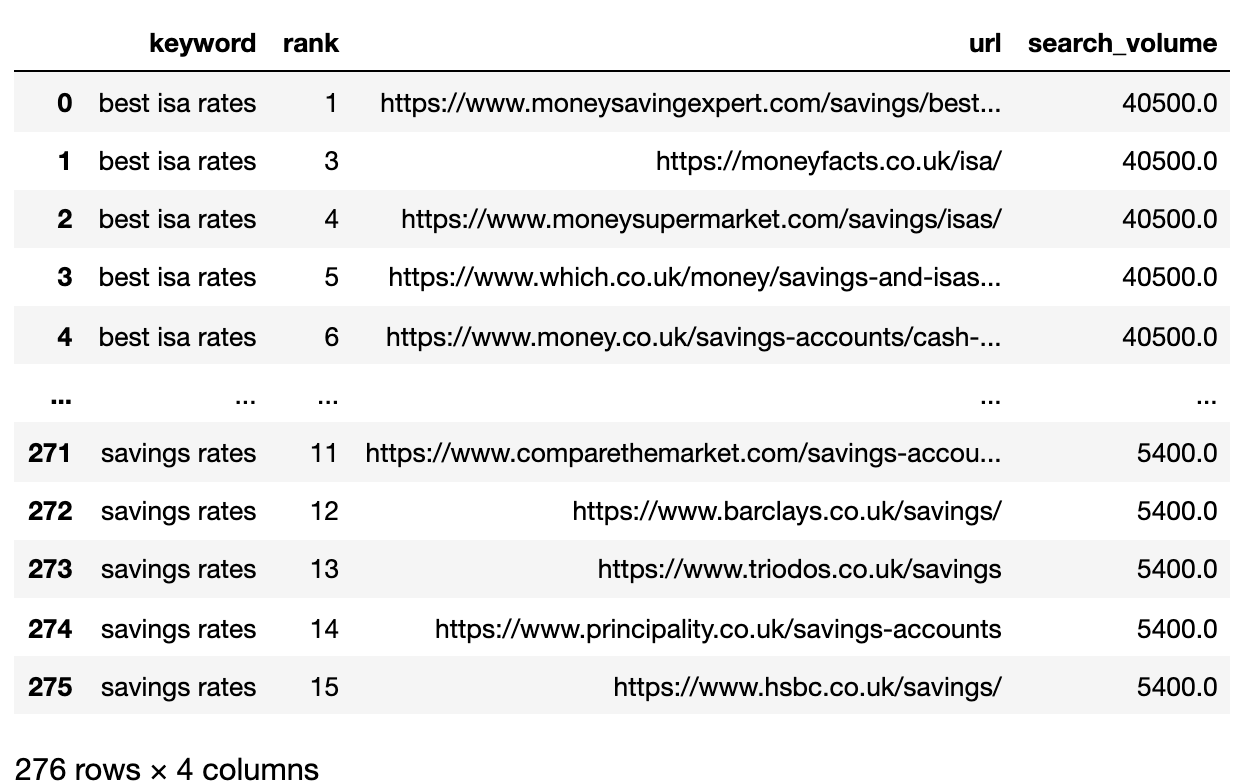
3. Konvertálja a rangsorolási URL -eket karakterláncra
Mivel több SERP eredmény URL -je van, mint a kulcsszavak, ezeket az URL -eket egyetlen sorba kell tömörítenünk a kulcsszó SERP ábrázolásához.
Így van:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df['serp_string'] = ''.join(df['url'])
return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Az alábbiakban bemutatjuk a SERP -t, amelyet az egyes kulcsszavakhoz egyetlen sorra tömörítenek.
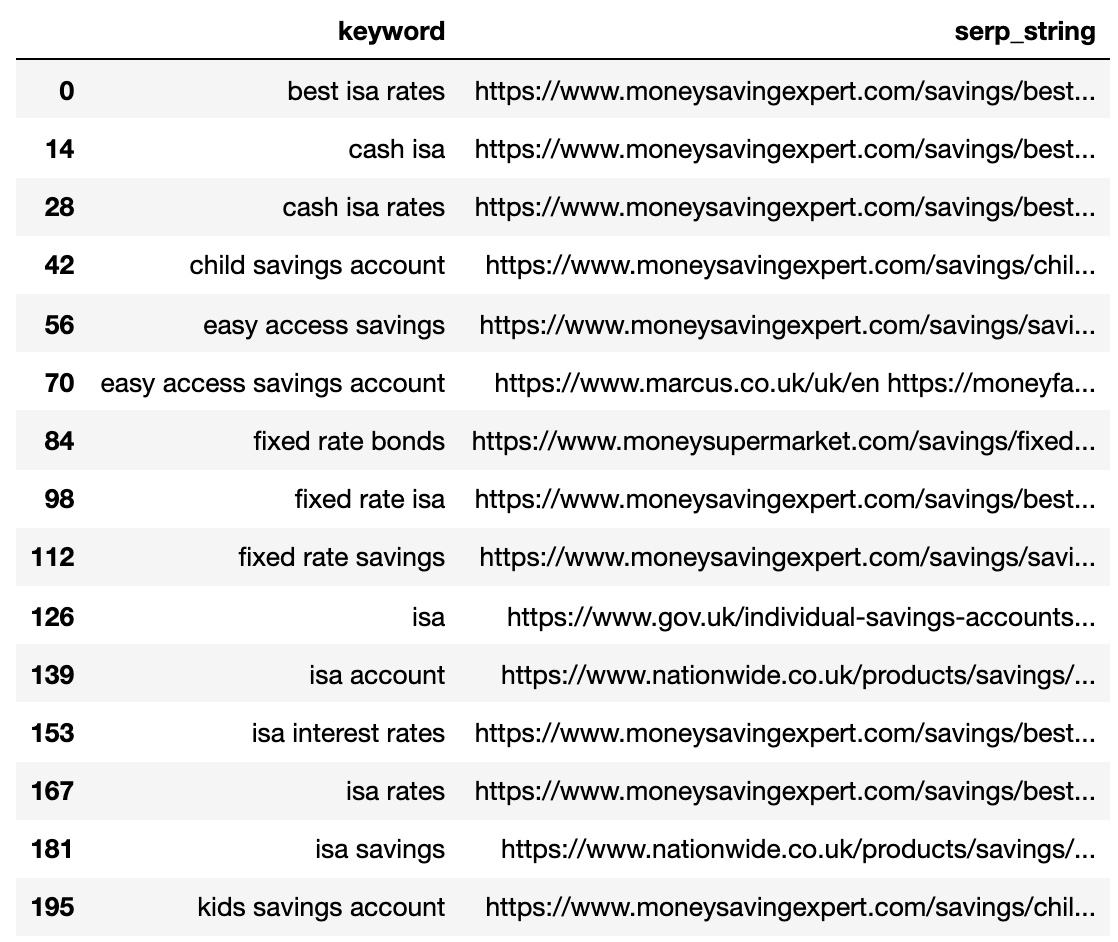
4. Hasonlítsa össze a SERP távolságát
Az összehasonlítás elvégzéséhez most minden kombinációra szükségünk van a SERP kulcsszóval, más párokkal párosítva:
# align serps
def serps_align(k, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'})
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'})
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

A fentiek az összes kulcsszó SERP pár kombinációt mutatják, így készen áll a SERP karakterlánc -összehasonlításra.
Nincs olyan nyílt forráskódú könyvtár, amely összehasonlítja a listaobjektumokat rendelés szerint, tehát a funkciót az alábbiakban írták.
A „SERP_COMPARE” funkció összehasonlítja a helyek átfedését és a SERP -k közötti helyek sorrendjét.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of form [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]

Most, hogy az összehasonlításokat végrehajtottuk, elkezdhetjük a klaszterezési kulcsszavakat.
Bármely kulcsszavat kezelünk, amelynek súlyozott hasonlósága legalább 40%.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
Most már megvan a potenciális téma neve, a SERP kulcsszavak és a keresési kötetek mindegyike.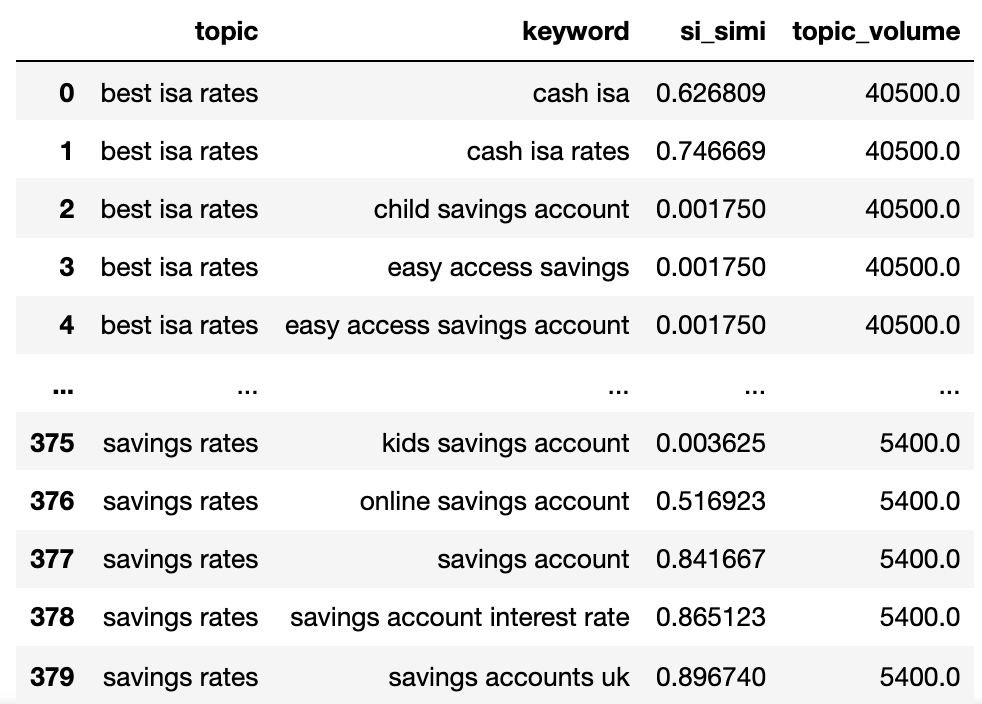
Megjegyzi, hogy a kulcsszót és a kulcsszó_t a téma és a kulcsszó átnevezték.
Most a Lambda technika alkalmazásával iteráljuk az adatkeret oszlopain.
A Lambda technika hatékony módja annak, hogy a sorok fölé iteráljon egy Pandas dataframe -ban, mivel a sorokat listára konvertálja, szemben a .iterrows () függvényt.
Itt megy:
queries_in_df = list(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
elif len(sim_topic_groups[keyw]) < len(sim_topic_groups[topc]):
sim_topic_groups[topc].append(keyw)
[sim_topic_groups[topc].append(x) for x in sim_topic_groups.get(keyw)]
sim_topic_groups.pop(keyw)
elif len(sim_topic_groups[keyw]) == len(sim_topic_groups[topc]):
if sim_topic_groups[keyw] == topc and sim_topic_groups[topc] == keyw:
sim_topic_groups.pop(keyw)
elif si < simi_lim:
if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)):
non_sim_topic_groups[keyw] = [keyw]
if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)):
non_sim_topic_groups[topc] = [topc]
Az alábbiakban bemutatjuk az összes kulcsszót, amely a keresési szándékkal csoportosított csoportokba csoportosul:
{1: ['fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'],
2: ['child savings account', 'kids savings account'],
3: ['savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'],
4: ['isa account', 'isa', 'isa savings']}Ragaszkodjunk egy adatkeretbe:
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
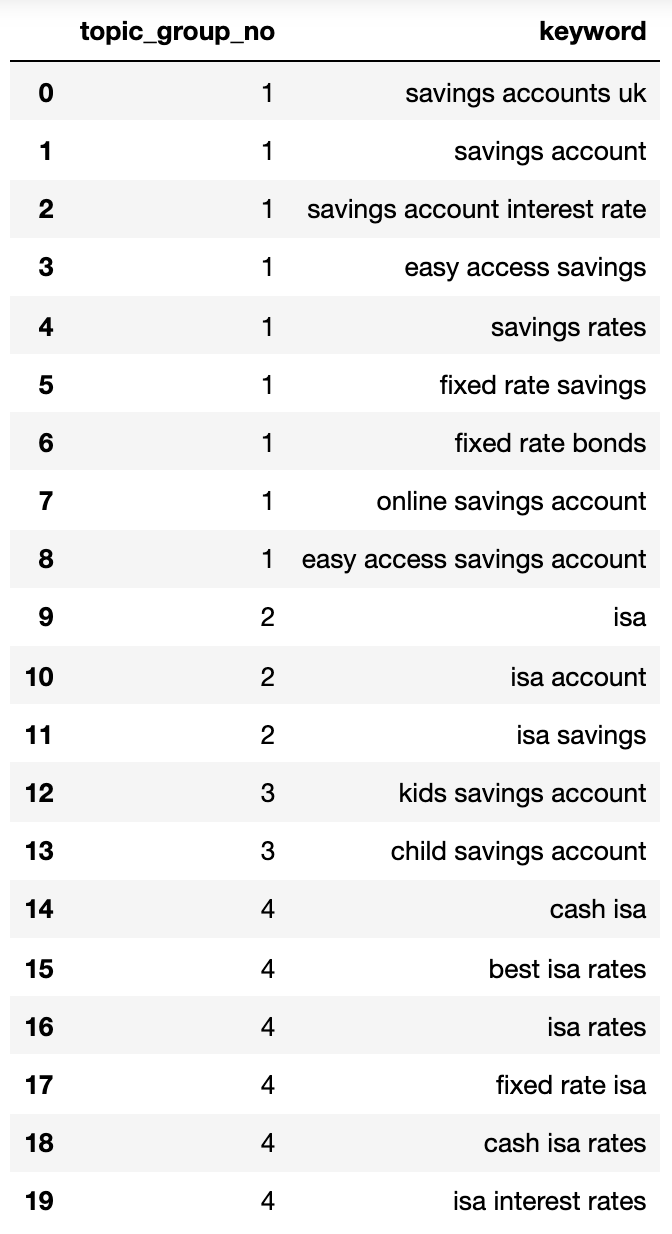
A fenti keresési szándékú csoportok a kulcsszavak jó közelítését mutatják bennük, amit a SEO szakértője valószínűleg elér.
Noha csak egy kis kulcsszót használtunk, a módszer nyilvánvalóan ezrekre (ha nem is több) méretezhető.
A kimenetek aktiválása a keresés jobbá tétele érdekében
Természetesen a fentiek tovább lehetne venni a neurális hálózatok felhasználásával, a rangsorolási tartalom feldolgozását a pontosabb klaszterek és a klasztercsoportok elnevezése érdekében, ahogyan az ott található kereskedelmi termékek egy része már megteszi.
Egyelőre ezzel a kimenetkel:
- Helyezze be ezt a saját SEO irányítópultrendszereibe, hogy a trendek és a SEO jelentése értelmesebbé tegye.
- Készítsen jobban fizetett keresési kampányokat a Google hirdetési fiókjainak felépítésével a magasabb minőségű pontszám keresési szándékával.
- Egyesítse a redundáns aspektus e -kereskedelmi keresési URL -eket.
- Felépítse a bevásárlóhely taxonómiáját a keresési szándék szerint egy tipikus termékkatalógus helyett.
Biztos vagyok benne, hogy vannak több olyan alkalmazás, amelyet még nem említettem – nyugodtan kommentálhassa azokat a fontosokat, amelyeket még nem említettem.
Mindenesetre a SEO kulcsszó -kutatása csak egy kicsit skálázhatóbb, pontosabb és gyorsabb!
Töltse le a teljes kódot itt a saját használatához.
