
![Structured Data In 2024: Key Patterns Reveal The Future Of AI Discovery [Data Study]](https://eoldal.hu/wp-content/uploads/2024/12/1734114885_A-kulcsmintak-felfedik-az-AI-felfedezesenek-jovojet.png)
A strukturált adatkörnyezet 2024-ben jelentős átalakuláson ment keresztül az AI-alapú keresés térnyerése, a géppel olvasható tartalom növekvő jelentősége, valamint a nagy nyelvi modellek tényadatokba való alapozásának szükségessége miatt.
A legújabb szerint HTTP Archívum webes almanachja16,9 millió webhely strukturált adatait elemezve egyértelmű elmozdulást mutatunk ki a hagyományos SEO-megvalósításról a kifinomultabb tudásgráf-fejlesztés felé, amely az AI-felderítő rendszereket támogatja.
Míg a Google 2023-ban megszüntetett bizonyos bővített találatokat, például a GYIK-et és a Útmutatókat, egyidejűleg példátlan számú új strukturált adattípust vezetett be, beleértve a járműadatokat, a tanfolyami információkat, az üdülési bérleteket, a profiloldalakat és a 3D-s termékmodelleket.
2024 februárjában kibővítette a termékváltozatok és a GS1 Digital Link támogatását, majd márciusban bevezették a strukturált adatkörözők bétaverzióját.
Ez a gyors evolúció egy érlelő ökoszisztémát jelez, ahol a strukturált adatok nemcsak a keresési láthatóságot szolgálják, hanem a tényszerű mesterséges intelligencia válaszok, a képzési nyelvi modellek és a továbbfejlesztett digitális termékélmények alapját is képezik.
Elemzés és módszertan
A cikkben bemutatott betekintések a HTTP Archívum webes almanachjának Strukturált adatok című fejezetének 2024-es kiadásán alapulnak. Az éves jelentés a web állapotát elemzi a strukturált adatok megvalósításának értékelésével 16,9 millió webhelyen. Ezek az adatkészletek vannak nyilvánosan lekérdezhető a BigQuery-n a táblázatokban `httparchive.all.*` táblázatok a dátumhoz date="2024-06-01" és olyan eszközökre támaszkodik, mint a WebPageTest, a Lighthouse és a Wappalyzer, hogy rögzítse a strukturált adatformátumokra, az átvételi trendekre és a teljesítményre vonatkozó mutatókat.
A strukturált adatok átvételének trendjei
Az elemzés lenyűgöző növekedést mutat a főbb strukturált adatformátumok között:
- A JSON-LD elterjedtsége eléri a 41%-ot (+7% Y/Y).
- Az RDFa továbbra is vezető szerepet tölt be 66%-os jelenléttel (+3% év/év).
- Az Open Graph megvalósítása 64%-ra nő (+5% év/év).
- Az X (Twitter) metacímke-használat 45%-ra nő (+8% YoY).
Ez a széles körben elterjedt elterjedtség azt jelzi, hogy a szervezetek nem csak a keresés láthatósága érdekében fektetnek be a strukturált adatokba, hanem azért is, hogy a mesterséges intelligencia és a robotok megértsék és javítsák digitális élményeiket.
AI felfedezési és tudásgrafikonok
A strukturált adatok és a mesterséges intelligencia rendszerek közötti kapcsolat összetett módon fejlődik.
Míg sok generatív mesterséges intelligencia keresőmotor még mindig fejleszti a strukturált adatok kiaknázására irányuló megközelítését, az olyan bevált platformok, mint a Bing Copilot, a Google Gemini és a speciális eszközök, mint a SearchGPT, máris bizonyítják az entitásalapú megértés értékét, különösen a helyi lekérdezések és a tények érvényesítése terén.
Képzés és entitásmegértés
A generatív mesterséges intelligencia keresőmotorok hatalmas adathalmazokra vannak kiképezve, amelyek strukturált adatjelölést tartalmaznak, és befolyásolják, hogyan:
- Az entitások (termékek, helyek, szervezetek) felismerése és kategorizálása.
- Földi válaszok. Ezt látjuk az olyan rendszerekben, mint a DataGemma, amelyek strukturált adatokat használnak a válaszok ellenőrizhető tényekbe való megalapozására.
- A különböző adatpontok közötti kapcsolatok megértése. Ez különösen akkor nyilvánvaló, ha a schema.org-ot világszerte hiteles forrásokból származó adatkészletek összesítésére használják.
- Folyamatspecifikus lekérdezéstípusok, például helyi üzleti és termékkeresések.
Ez a képzés meghatározza, hogy az AI-rendszerek hogyan értelmezik a lekérdezéseket és válaszolnak rájuk, különösen az alábbiakban:
- Helyi üzleti lekérdezések, ahol az entitásattribútumok megfelelnek a strukturált adatmintáknak.
- A kereskedő által biztosított strukturált adatokat tükröző terméklekérdezések.
- Tudáspanel információk, amelyek igazodnak az entitásdefiníciókhoz.
Keresőmotor integráció
A különböző platformok a strukturált adatok hatását a következők révén mutatják be:
- Hagyományos keresés: Bővített eredmények és tudáspanelek, amelyek közvetlenül strukturált adatokon alapulnak.
- AI Search integráció:
- A Bing Copilot továbbfejlesztett eredményeket jelenít meg a strukturált entitásoknál.
- A Google Gemini tudásdiagram információit tükrözi.
- Speciális motorok, mint például a Perplexity.ai, amelyek demonstrálják az entitás megértését a helylekérdezésekben.
- A SERP-be integrált AI Sales Assistant legújabb Google-kísérlete a vásárlási lekérdezésekhez (Ez óriási! Itt van az X-en, a SERP Alert észlelte).
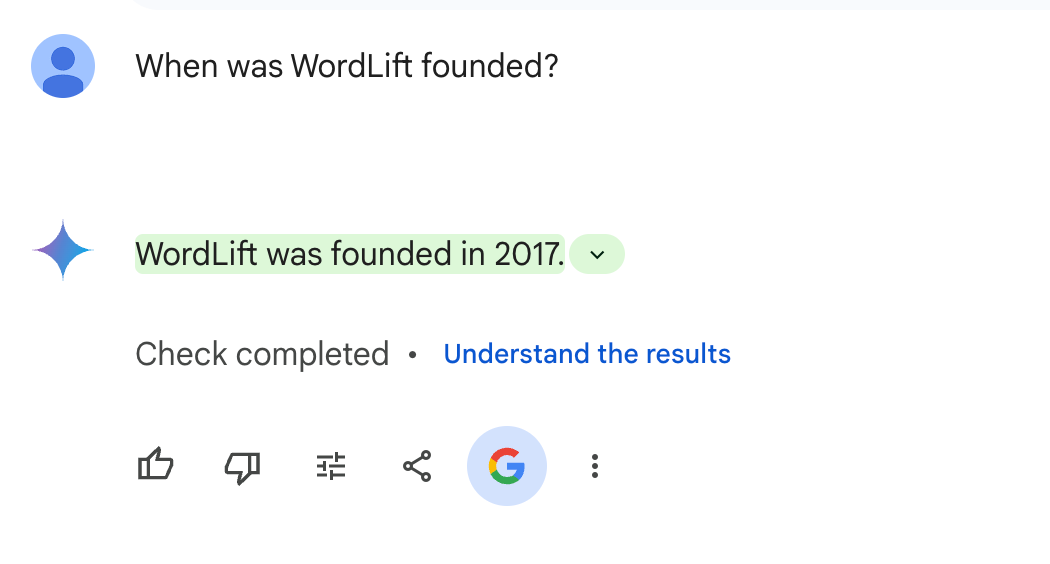
Íme egy példa az Ikrek és Google Keresés ugyanazt a tényt osztják.
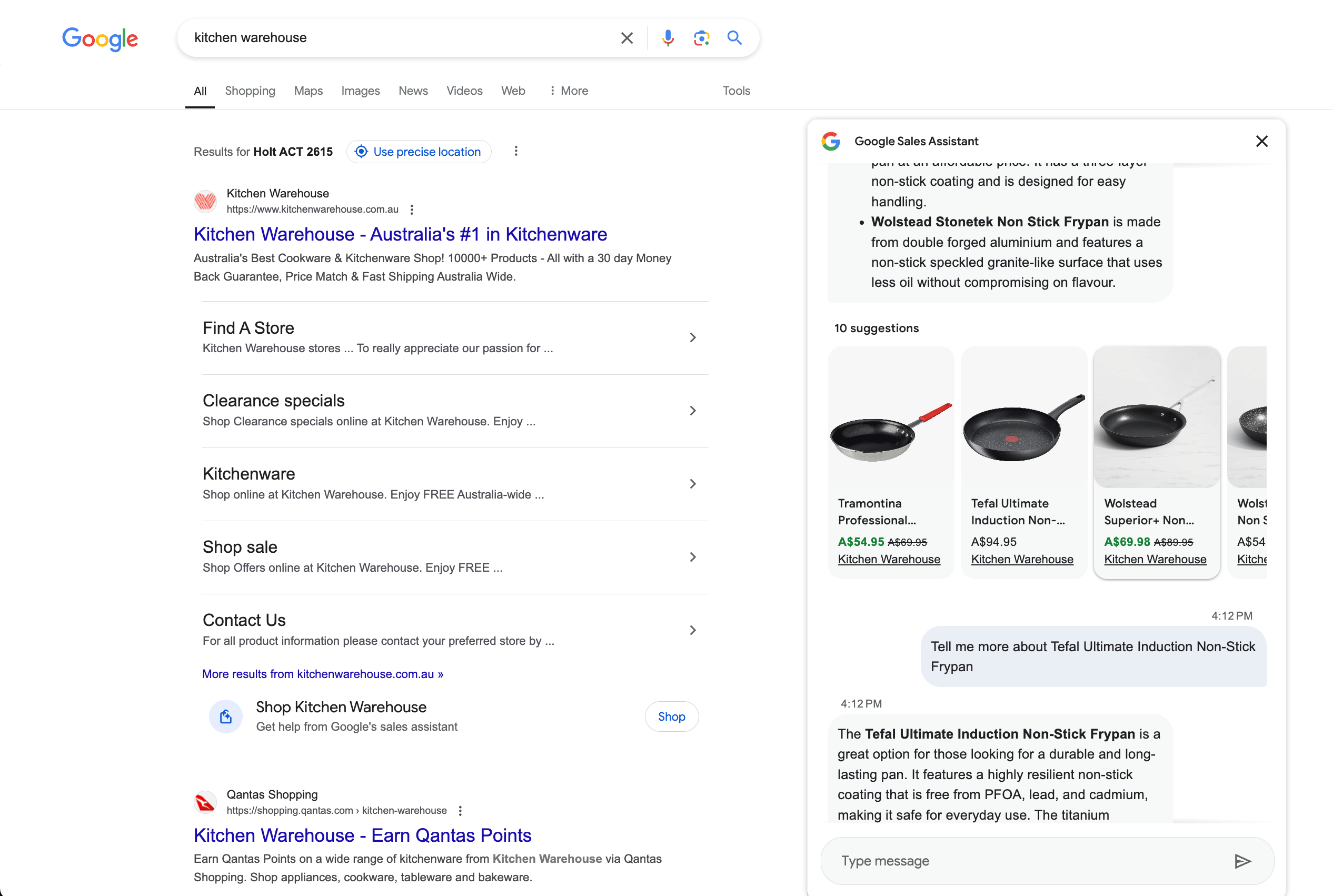
Adatok érvényesítése és ellenőrzése
A strukturált adatok ellenőrzési mechanizmusokat biztosítanak:
- Tudásgrafikonok: Az olyan rendszerek, mint a Google Data Commons, strukturált adatokat használnak a tények ellenőrzésére.
- Edzőkészletek: A Schema.org jelölés megbízható képzési példákat hoz létre az entitásfelismeréshez.
- Érvényesítési folyamatok: A tartalomgeneráló eszközök, mint például a WordLift, strukturált adatokat használnak az AI-kimenetek ellenőrzésére.
A legfontosabb különbség az, hogy a strukturált adatok nem befolyásolják közvetlenül az LLM-válaszokat, hanem inkább a mesterséges intelligencia keresőmotorjait alakítják a következők révén:
- Strukturált jelölést tartalmazó képzési adatok.
- A megértést irányító entitásosztály-definíciók.
- Integráció a hagyományos keresési gazdag találatokkal.
Ez egyre fontosabbá teszi a strukturált adatok megvalósítását a láthatóság szempontjából mind a hagyományos, mind az AI-alapú keresési platformokon.
Ahogy belépünk az AI Discovery új korszakába, a strukturált adatokba való befektetés már nem csak a SEO-ról szól – a szemantikai réteg felépítéséről van szó, amely lehetővé teszi a gépek számára, hogy valóban megértsék és pontosan reprezentálják, ki vagy.
Szemantikus SEO evolúció: A strukturált adatoktól a szemantikai adatokig
A SEO gyakorlata szemantikus SEO-vá fejlődött, a hagyományos kulcsszóoptimalizáláson túlmenően a szemantikai megértést is magában foglalja:
Entitás alapú optimalizálás
- Koncentráljon a világos entitásdefiníciókra és kapcsolatokra.
- Átfogó entitásattribútumok megvalósítása.
- A sameAs tulajdonságok stratégiai használata az entitás egyértelművé tételéhez.
Tartalmi hálózatok
- Összekapcsolt tartalomklaszterek fejlesztése.
- Tiszta forrásmegjelölés és szerzői jelölés.
- Rich media kapcsolat meghatározásai.
Legfontosabb megvalósítási minták a JSON-LD-ben
Tartalom közzététele
A több millió webhely strukturált adatmintáinak elemzése három domináns megvalósítási trendet tár fel a tartalommegjelenítők számára.
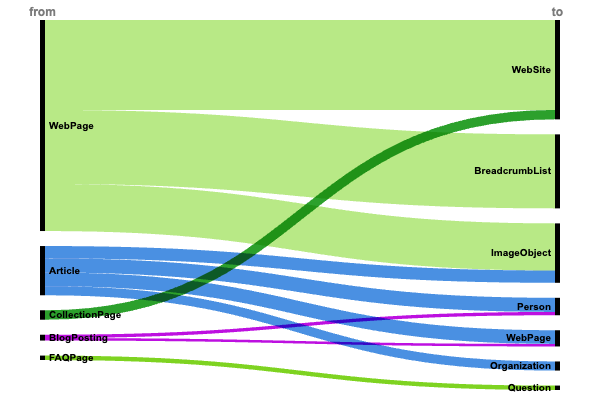
Weboldal szerkezete és navigáció (+6 millió megvalósítás)
A WebPage → isPartOf → WebSite (5,8 millió) és a WebPage → navigációs útvonal → BreadcrumbList (4,8 millió) kapcsolatok dominanciája azt mutatja, hogy a nagyobb webhelyek előnyben részesítik az egyértelmű webhely-architektúrát és a navigációs útvonalakat.
A webhelystruktúra továbbra is a strukturált adatok megvalósításának alapja, ami arra utal, hogy a keresőmotorok nagymértékben támaszkodnak ezekre a jelekre a tartalomhierarchia megértéséhez.
Tartalommegjelölés és jogosultság
Erős minták jelennek meg a tartalom-hozzárendelés körül:
- Cikk → szerző → Személy (925 000).
- Cikk → kiadó → Szervezet (597 000).
- Blogbejegyzés → szerző → Személy (217 000).
A szerzőségre és a szervezeti attribúcióra való összpontosítás az EEAT-jelek és a tartalomjogosultság növekvő jelentőségét tükrözi a keresési algoritmusokban.
Rich Media integráció
A képjelölések következetes megvalósítása a tartalomtípusok között:
- Weboldal → elsődlegesImageOfPage → ImageObject (3 millió)
- Cikk → kép → ImageObject (806 000)
A médiakapcsolatok magas gyakorisága azt jelzi, hogy a kiadók felismerik a strukturált vizuális tartalom értékét mind a keresési láthatóság, mind a felhasználói élmény szempontjából.
Az adatok azt sugallják, hogy a kiadók túllépnek az alapvető SEO jelöléseken, és átfogó, géppel olvasható tartalomgrafikonokat készítenek, amelyek támogatják a hagyományos keresést és a kialakulóban lévő AI-felderítő rendszereket.
Helyi üzlet és kiskereskedelem
A helyi üzleti strukturált adatok megvalósításának elemzése három kritikus mintacsoportot tár fel, amelyek dominálnak a helyalapú jelöléseknél.
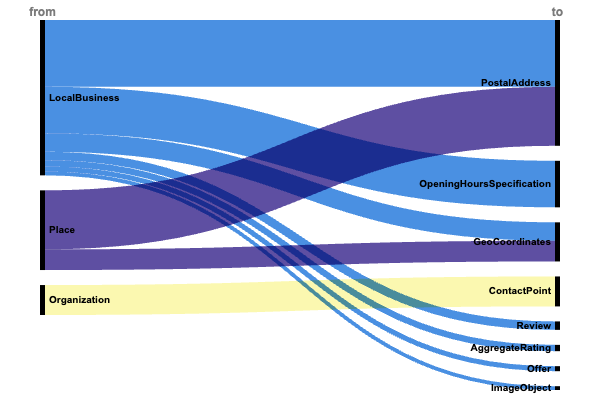
Hely és hozzáférhetőség (+1,4 millió megvalósítás)
A fizikai helymegjelölés széles körű elterjedése bizonyítja annak alapvető fontosságát:
- LocalBusiness → cím → Postacím (745 000).
- Hely → cím → Postacím (658 000).
- Szervezet → contactPoint → ContactPoint (334 000).
- LocalBusiness → openHoursSpecification (519 000).
Ezen alapvető működési részletek erős jelenléte azt sugallja, hogy a helyi keresés láthatóságának alapvető rangsoroló tényezői.
Földrajzi pontosság
A földrajzi koordináták jelentős megvalósítása azt mutatja, hogy a pontos helyre összpontosítanak:
- Hely → geo → GeoCoordinates (231 000).
- LocalBusiness → geo → GeoCoordinates (205 000).
A helymeghatározásnak ez a kettős megközelítése (cím + koordináták) azt jelzi, hogy a keresőmotorok fontosnak tartják a pontos földrajzi helymeghatározást a helyi keresés pontossága érdekében.
Bizalmi jelek
Egy kisebb, de figyelemre méltó mintacsoport a hírnévre összpontosít:
- LocalBusiness → vélemény → Vélemény (94 000)
- LocalBusiness → aggregateRating → AggregateRating (70 000)
- LocalBusiness → fotók → ImageObject (42 000)
- LocalBusiness → makeOffer → Ajánlat (56 000)
Bár ritkábban alkalmazzák ezeket a bizalomépítő elemeket, gazdagabb helyi üzleti egységeket hoznak létre, amelyek támogatják a keresés láthatóságát és a felhasználói döntéshozatalt.
E-kereskedelem (bővített lista)
Az e-kereskedelmi strukturált adatok elemzése olyan kifinomult megvalósítási mintákat tár fel, amelyek a termékfelfedezésre és a konverzióoptimalizálásra összpontosítanak.

Alapvető termékinformációk (+4,7 millió megvalósítás)
Az alaptermékek jelölésének dominanciája mutatja alapvető fontosságát:
- Termék → ajánlatok → Ajánlat (3,1 millió).
- Ajánlat → eladó → Szervezet (2,2 millió).
- Termék → mainEntityOfPage → Weboldal (1,5 millió).
Az alapvető termékkapcsolatok magas elterjedtségi aránya azt jelzi, hogy kritikus szerepet játszanak a termékek felfedezésében és a kereskedők láthatóságában.
Bizalom és társadalmi bizonyíték
A felülvizsgálattal kapcsolatos jelölések jelentős megvalósítása:
- Termék → vélemény → Vélemény (490 000).
- Termék → aggregateRating → AggregateRating (201 000).
- Vélemény → véleményÉrtékelés → Értékelés (110 000).
A felülvizsgálati jelölések jelentős jelenléte azt sugallja, hogy a társadalmi bizonyíték továbbra is kulcsfontosságú az e-kereskedelmi konverzió szempontjából.
Továbbfejlesztett termékkontextus
A gazdag termékattribútum megvalósítása a részletes termékinformációkra összpontosít:
- Termék → márka → Márka (315 000).
- Termék → kiegészítő Tulajdon → PropertyValue (253 000).
- Termék → kép → ImageObject (182 000).
- Ajánlat → szállítási részletek → AjánlatSzállítási részletek (151 000).
- Ajánlat → árspecifikáció → Árspecifikáció (42 000).
- AggregateOffer → ajánlatok → Ajánlat (69 000).
A termékattribútumoknak ez a többrétegű megközelítése átfogó termékentitásokat hoz létre, amelyek támogatják a keresés láthatóságát és a felhasználói döntéshozatalt.
Jövőbeli kilátások
A strukturált adatok szerepe túlmutat hagyományos SEO-eszközén, amely bővített kivonatokat és speciális keresési funkciókat biztosít. A mesterséges intelligencia felfedezésének korában a strukturált adatok a gépi megértés kritikus elemévé válnak, megváltoztatva a tartalom értelmezésének és összekapcsolásának módját az interneten. Ez az elmozdulás arra készteti az ipart gondoljon túl a Google-központú optimalizálásonamely a strukturált adatokat egy szemantikai és mesterséges intelligenciával integrált web alapvető összetevőjeként tartalmazza.
A strukturált adatok biztosítják az állványzatot az összekapcsolt, géppel olvasható keretrendszerek létrehozásához, amelyek létfontosságúak az olyan feltörekvő mesterséges intelligencia-alkalmazások számára, mint a párbeszédes keresés, a tudásgráfok és a (Graph) visszakereséssel kiegészített generációs (GraphRAG vagy RAG) rendszerek. Ez az evolúció kettős megközelítést igényel: a használható sématípusok kihasználása az azonnali SEO-előnyök (gazdag eredmények) érdekében, miközben átfogó, leíró sémákba fektet be, amelyek szélesebb adatökoszisztémát építenek fel.
A jövő a strukturált adatok, a szemantikai modellezés és a mesterséges intelligencia által vezérelt tartalomfelderítő rendszerek metszéspontjában rejlik. Egy holisztikusabb nézet elfogadásával a szervezetek elmozdulhatnak a strukturált adatok taktikai keresőoptimalizálásként való használatától, hanem stratégiai rétegként pozícionálhatják azokat az AI interakcióinak működtetéséhez és a különféle platformokon való megtalálhatóság biztosításához.
Köszönetnyilvánítás és Köszönetnyilvánítás
Ez az elemzés nem lenne lehetséges a HTTP Archívum csapatának és a Web Almanach közreműködőinek elkötelezett munkája nélkül. Külön köszönet:
A teljes Web Almanach Strukturált adatok fejezete még mélyebb betekintést nyújt a strukturált adatok megvalósításának fejlődő környezetébe.
Ahogy haladunk a mesterséges intelligencia által vezérelt jövő felé, a strukturált adatok stratégiai jelentősége tovább fog nőni.
