

Marketingszakemberekként szeretjük a nagyszerű tölcsért. Világossá teszi stratégiáink működését. Vannak konverziós arányaink, és nyomon tudjuk követni az ügyfelek útját a felfedezéstől a konverzióig. De a mai mesterséges intelligencia világában a tölcsérünk elsötétült.
Még nem tudjuk teljesen mérheti a láthatóságot az olyan mesterséges intelligencia-élményekben, mint a ChatGPT vagy a Perplexity. Míg a feltörekvő eszközök részleges betekintést nyújtanak, adataik nem teljes körűek vagy következetesen megbízhatóak. A hagyományos mutatók, például a megjelenítések és a kattintások még mindig nem mondják el a teljes történetet ezeken a területeken, így a marketingesek újfajta mérési réssel néznek szembe.
Az egyértelműség érdekében nézzük meg, mit tudunk és mit nem tudunk a strukturált adatok (más néven sémajelölés) értékének méréséről. Ha mindkét oldalt megértjük, arra összpontosíthatunk, hogy mi ma mérhető és ellenőrizhető, és hol rejlenek a lehetőségek, mivel a mesterséges intelligencia megváltoztatja azt, ahogyan az ügyfelek hogyan fedezik fel márkáinkat és kapcsolódnak be azokkal.
Miért nem valós a legtöbb „AI láthatósági” adat?
Az AI éhséget keltett a mérőszámok iránt. A marketingszakemberek, akik kétségbeesetten próbálják számszerűsíteni, mi történik a tölcsér tetején, új eszközök hulláma felé fordulnak. E platformok közül sok új méréseket hoz létre, például „márkajogot az AI-platformokon”, amelyek nem reprezentatív adatokon alapulnak.
Egyes eszközök például úgy próbálják mérni az „AI promptokat”, hogy a rövid kulcsszókifejezéseket úgy kezelik, mintha egyenértékűek lennének a ChatGPT vagy a Perplexity fogyasztói lekérdezéseivel. De ez a megközelítés félrevezető. A fogyasztók hosszabb, kontextusban gazdag üzeneteket írnak, amelyek messze túlmutatnak azon, amit a kulcsszóalapú mutatók sugallnak. Ezek a promptok árnyaltak, beszélgetősek és nagymértékben személyre szabottak – nem hasonlítanak a hagyományos hosszú farkú lekérdezésekhez.
Ezek a szintetikus mutatók hamis kényelmet nyújtanak. Elvonják a figyelmet arról, ami valójában mérhető és ellenőrizhető. A tény az, hogy a ChatGPT, a Perplexity és még a Google mesterséges intelligencia áttekintései sem biztosítanak világos és átfogó láthatósági adatokat.
Tehát mit mérhetünk, ami valóban befolyásolja a láthatóságot? Strukturált adatok.
Mi az AI-keresés láthatósága?
Mielőtt belevágna a mérőszámokba, érdemes meghatározni az „AI-keresés láthatóságát”. A hagyományos SEO-ban a láthatóság a keresési eredmények egyik oldalán való megjelenést vagy a kattintások elérését jelentette. A mesterséges intelligencia által vezérelt világban a láthatóság azt jelenti, hogy mind a keresőmotorok, mind az AI-rendszerek megértik, megbíznak benneteket és hivatkoznak ránk. A strukturált adatok szerepet játszanak ebben az evolúcióban. Segít meghatározni, összekapcsolni és tisztázni a márka digitális entitásait, hogy a keresőmotorok és az AI-rendszerek megértsék azokat.
Az ismertek: Mit tudunk magabiztosan mérni a strukturált adatok esetében
Beszéljünk arról, hogy mi ismert és mérhető ma a strukturált adatok tekintetében.
Megnövelt átkattintási arány a gazdag eredményekből
A negyedéves üzleti áttekintésünk adataiból azt látjuk, hogy a strukturált adatok oldalakon történő implementálásával a tartalom gazdag eredményt ér el, és a vállalati márkák folyamatosan növekedést tapasztalnak az átkattintási arányban. A Google jelenleg több mint 30 típusú bővített találatot támogat, amelyek továbbra is megjelennek az organikus keresésben.
Belső adataink szerint például 2025 harmadik negyedévében egy háztartási gépipari vállalati márka 300%-kal nőtt az átkattintási arány termékoldalakon, amikor gazdag eredményt ítéltek oda. A gazdag találatok továbbra is láthatóságot és konverziós nyereséget biztosítanak az organikus keresésből.
Megnövekedett nem márkajelzésű kattintások száma a robusztus entitás-összekapcsolásból
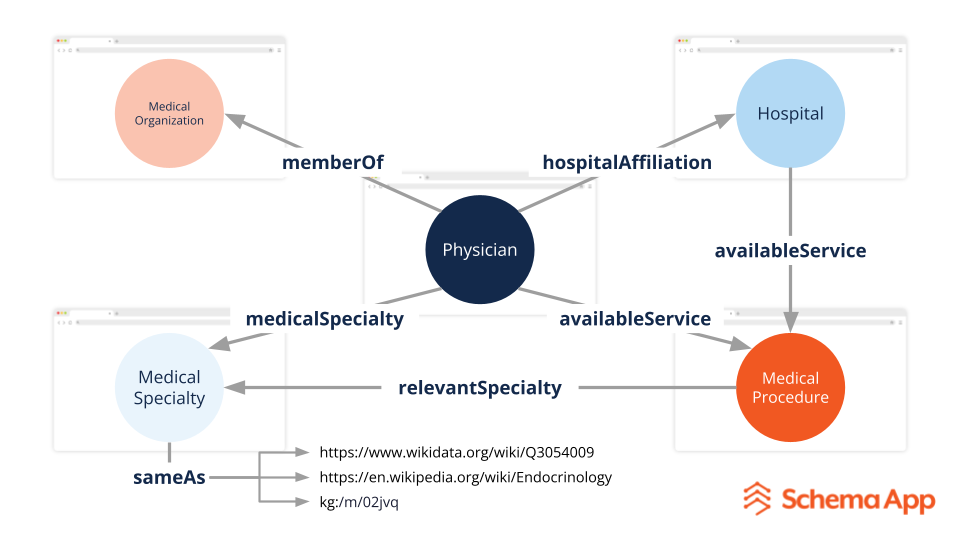
Fontos különbséget tenni az alapvető sémajelölés és a robusztus sémajelölés között az entitások összekapcsolásával, amely tudásgráfot eredményez. A sémajelölés leírja, hogy mi van az oldalon. Az entitások összekapcsolása összekapcsolja ezeket a dolgokat más, jól meghatározott entitásokkal a webhelyen és a weben, és olyan kapcsolatokat hoz létre, amelyek meghatározzák a jelentést és a kontextust.
Az entitás egy egyedi és megkülönböztethető dolog vagy fogalom, mint például egy személy, termék vagy szolgáltatás. Az entitások összekapcsolása meghatározza, hogy ezek az entitások hogyan viszonyulnak egymáshoz, akár külső hiteles forrásokon keresztül, mint a Wikidata és a Google tudásdiagramja, vagy a saját belső tartalmi tudásdiagramja.
Képzeljünk el például egy oldalt egy orvosról. A sémajelölés az orvost írja le. Robusztus, szemantikus A markup a Wikidatához és a Google tudásgráfjához is kapcsolódna, hogy meghatározza szakterületüket, miközben összekapcsolja az általuk nyújtott kórházakat és egészségügyi szolgáltatásokat.
AIO láthatóság
A hagyományos SEO mérőszámok még nem tudják közvetlenül mérni az AI-élményt, de egyes platformok képesek azonosítani néhány olyan esetet, amikor egy márka megemlítésre kerül az AI Áttekintés (AIO) eredményében.
A BrightEdge jelentés kutatása szerint az entitásalapú SEO gyakorlatok alkalmazása erősebb AI láthatóságot eredményez. A jelentés megjegyezte:
„A mesterséges intelligencia előnyben részesíti az ismert, megbízható entitásoktól származó tartalmat. Hagyja abba a töredezett kulcsszavakra való optimalizálást, és kezdjen el átfogó témaköri tekintélyt építeni. Adataink azt mutatják, hogy a hiteles tartalom háromszor nagyobb valószínűséggel hivatkozik a mesterséges intelligencia válaszaiban, mint a szűken vett oldalak.”
Ismeretlenek: Amit még nem tudunk mérni
Bár a sémajelölésben szereplő entitások hatását mérhetjük a meglévő SEO-metrikákon keresztül, még nincs közvetlen rálátásunk arra, hogy ezek az elemek hogyan befolyásolják a nagy nyelvi modell (LLM) teljesítményét.
Hogyan használják az LLM-ek a sémajelölést
A láthatóság a megértéssel kezdődik – a megértés pedig a strukturált adatokkal.
Erre egyre több a bizonyíték. A Microsoft 2025. október 8-i blogbejegyzésében, „A tartalom optimalizálása az AI-keresés válaszaiba (Microsoft Advertising)” című blogbejegyzésében Krishna Madhaven, a Microsoft Bing fő termékmenedzsere ezt írta:
„A marketingszakemberek számára az a kihívás, hogy tartalmuk könnyen érthető legyen, és olyan strukturált legyen, amelyet az AI-rendszerek is használhatnak.”
Hozzátette:
„A séma egy olyan kódtípus, amely segít a keresőmotoroknak és az AI-rendszereknek megérteni az Ön tartalmát.”
Hasonlóképpen, a Google cikke „A legjobb módszerek annak biztosítására, hogy tartalmai jól teljesítsenek a Google AI-élményeiben a Keresésben” című cikke megerősíti, hogy „a strukturált adatok hasznosak a tartalommal kapcsolatos információk gépi olvasható módon történő megosztásához”.
Miért helyezi előtérbe a Google és a Microsoft is a strukturált adatokat? Ennek egyik oka a költség és a hatékonyság lehet. A strukturált adatok segítenek tudásgrafikonok felépítésében, amelyek a pontosabb, magyarázhatóbb és megbízhatóbb mesterséges intelligencia alapjául szolgálnak. A kutatások kimutatták, hogy a tudásgrafikonok csökkenthetik a hallucinációkat és javíthatják az LLM-ek teljesítményét:
Noha magát a sémajelölést általában nem közvetlenül az LLM-ek betanítására használják fel, a visszakeresési fázis a visszakereséssel kiegészített generációs (RAG) rendszerekben döntő szerepet játszik abban, hogy az LLM-ek hogyan válaszolnak a lekérdezésekre. A legutóbbi munkák során a Microsoft GraphRAG rendszere tudásgráfot hoz létre (entitás- és relációkivonáson keresztül) szöveges adatokból, és ezt a grafikont felhasználja a visszakeresési folyamatában. Kísérleteik során a GraphRAG gyakran felülmúlja az alapszintű RAG-megközelítést, különösen olyan feladatoknál, amelyek többugrásos érvelést vagy különböző entitások alapozását igénylik.
Ez segít megmagyarázni, hogy az olyan vállalatok, mint a Google és a Microsoft, miért ösztönzik a vállalati márkákat a strukturált adatokba való befektetésre – ez a kötőszövet, amely segít a mesterséges intelligencia rendszereknek pontos, kontextus szerinti információk lekérésében.
Az oldalszintű SEO-n túl: Tudásgrafikonok készítése
Lényeges különbség van aközött, hogy egyetlen oldalt SEO-ra optimalizálunk, és olyan tudásdiagramot hozunk létre, amely összekapcsolja a vállalat teljes tartalmát. Egy közelmúltbeli interjúban Robby Steinnel, a Google termékért felelős alelnökével megjegyezték, hogy az AI-lekérdezések több tucat allekérdezést tartalmazhatnak a színfalak mögött (lekérdezés fan-out néven). Ez a komplexitás olyan szintjére utal, amely holisztikusabb megközelítést igényel.
Ahhoz, hogy ebben a környezetben sikeresek lehessenek, a márkáknak túl kell lépniük az oldalak optimalizálásán, és ehelyett tudásgrafikonokat, vagy inkább egy olyan adatréteget kell felépíteniük, amely üzleti tevékenységük teljes kontextusát reprezentálja.
A szemantikus webes vízió, megvalósult
Ami igazán izgalmas, az az, hogy megérkezett a szemantikus web jövőképe. Ahogy Tim Berners-Lee, Ora Lassila és James Hendler írta a „The Semantic Web” (Scientific American, 2001) című könyvében:
„A szemantikus web lehetővé teszi a gépek számára, hogy megértsék a szemantikai dokumentumokat és adatokat, és lehetővé teszik az oldalról oldalra barangoló szoftverügynökök számára, hogy kifinomult feladatokat hajtsanak végre a felhasználók számára.”
Ma ezt látjuk, amikor a tranzakciók és lekérdezések közvetlenül az AI-rendszereken, például a ChatGPT-n belül történnek. A Microsoft már készül a következő szakaszra, amelyet gyakran „ügynöki webnek” neveznek. 2024 novemberében RV Guha – a Schema.org létrehozója, jelenleg a Microsoftnál – bejelentette az NLWeb nevű nyílt projektet. Az NLWeb célja, hogy „a leggyorsabb és legegyszerűbb módja annak, hogy webhelyét hatékonyan mesterségesintelligencia-alkalmazásokká alakítsák, lehetővé téve a felhasználók számára, hogy közvetlenül a természetes nyelv használatával kérdezzenek le a webhely tartalmáról, akárcsak egy AI-asszisztens vagy másodpilóta esetében.”
Egy közelmúltban Guhával folytatott beszélgetésem során elmondta, hogy az NLWeb víziója az, hogy az ügynökök végpontja legyen a webhelyekkel való interakcióban. Az NLWeb strukturált adatokat használ ehhez:
„Az NLWeb olyan félig strukturált formátumokat használ, mint a Schema.org… természetes nyelvi interfészek létrehozásához, amelyeket mind az emberek, mind az AI-ügynökök használhatnak.”
A Sötét Tölcsér Intelligenssé alakítása
Ahogy a ChatGPT-ben és a Perplexity-ben hiányoznak a márkateljesítmény mérésére szolgáló valós mérőszámok, a sémajelölésnek az AI láthatóságában betöltött szerepére vonatkozóan sem rendelkezünk még teljes mérőszámmal. De világos, következetes jelzéseink vannak a Google-tól és a Microsofttól, hogy az AI-tapasztalataik részben strukturált adatokat használnak a tartalom megértéséhez.
A marketing jövője a márkáké, amelyeket a gépek megértenek és amelyekben megbíznak. A strukturált adatok az egyik tényező ennek megvalósításában.
