

John Mueller, a Google nemrégiben válaszolt a Google Search Console-ban jelentett fantom noindex-hibákra vonatkozó kérdésre. Mueller azt állította, hogy ezek a jelentések valósak lehetnek.
Noindex A Google Search Console-ban
A noindex robots direktíva azon kevés parancsok egyike, amelyeknek a Google-nak engedelmeskednie kell, egyike azon kevés módoknak, amellyel a webhely tulajdonosa irányíthatja a Googlebotot, a Google indexelőjét.
Ennek ellenére nem teljesen ritka, hogy a keresőkonzol arról számol be, hogy nem tud indexelni egy oldalt egy noindex direktíva miatt, amelyen látszólag nincs noindex direktíva, legalábbis egyik sem látható a HTML-kódban.
Amikor a Google Search Console (GSC) „noindex” jelzéssel ellátott beküldött URL-t jelent, látszólag ellentmondásos helyzetet jelent:
- A webhely arra kérte a Google-t, hogy indexelje az oldalt egy webhelytérkép bejegyzésén keresztül.
- Az oldal jelzést küldött a Google-nak, hogy ne indexelje (noindex utasításon keresztül).
Zavarba ejtő üzenet a Search Console-tól, hogy egy oldal megakadályozza a Google-t az indexelésben, amikor a kiadó vagy a keresőoptimalizálás nem észleli, hogy ez kódszinten történik.
A kérdést feltevő személy a Bluesky-n közzétette:
„Az elmúlt 4 hónapban a webhely noindex hibát észlel (a „robots” metacímkében), amely nem hajlandó eltűnni a Search Console-ból. Sehol sem található noindex a webhelyen, sem a robots.txt. Ezt már megvizsgáltuk… Mi okozhatja ezt a hibát?”
A Noindex csak a Google számára jelenik meg
A Google munkatársa, John Mueller válaszolt a kérdésre, és megosztotta, hogy az általa vizsgált oldalakon mindig volt egy noindex, amely a Google számára jelent meg, ahol ilyesmi történt.
Mueller így válaszolt:
„A múltban olyan eseteket tapasztaltam, amikor valójában volt egy noindex, csak néha csak a Google-nak mutatták meg (amit még mindig nagyon nehéz hibakeresni). Ennek ellenére nyugodtan küldjön nekem néhány példa URL-t.”
Noha Mueller nem részletezte, hogy mi történik, vannak módszerek a probléma elhárítására, hogy megtudja, mi történik.
A Phantom Noindex hibák elhárítása
Lehetséges, hogy valahol van egy kód, amely miatt a noindex csak a Google számára jelenik meg. Előfordulhat például, hogy egy oldalon egy időben noindex volt, és egy szerveroldali gyorsítótár (például egy gyorsítótárazási bővítmény) vagy egy CDN (például a Cloudflare) tárolta a HTTP-fejléceket attól az időponttól kezdve, ami viszont a régi noindex fejléc megjelenítését okozta a Googlebotnak (mivel gyakran látogatja a webhelyet), miközben egy friss verziót szolgáltat a webhely tulajdonosának.
A HTTP-fejléc ellenőrzése egyszerű, sok HTTP-fejléc-ellenőrző található, mint ez a KeyCDN-nél vagy ez a SecurityHeaders.com-on.
Az 520-as kiszolgálófejléc-válaszkód az, amelyet a Cloudflare küld, amikor blokkol egy felhasználói ügynököt.
Képernyőkép: 520 Cloudflare válaszkód
Az alábbiakban a cloudflare által generált 200-as szerver válaszkód képernyőképe látható:
Képernyőkép: 200 szerver válaszkód
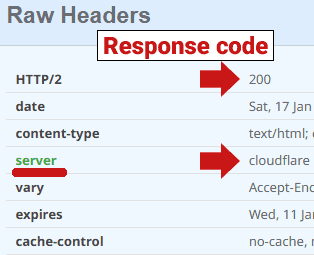
Ugyanazt az URL-t két különböző fejléc-ellenőrzővel ellenőriztem, az egyik fejlécellenőrző 520-as (blokkolt) szerver válaszkódot, a másik pedig 200-as (OK) válaszkódot adott vissza. Ez azt mutatja, hogy a Cloudflare milyen eltérően tud reagálni olyan dolgokra, mint a fejléc-ellenőrző. Ideális esetben próbálja meg több fejlécellenőrzővel ellenőrizni, hogy van-e konzisztens 520-as válasz a Cloudflare-től.
Abban a helyzetben, amikor egy weboldal kizárólag a Google számára mutat valamit, ami egyébként nem látható a kódot megtekintő személy számára, akkor rá kell vennie a Google-t, hogy egy tényleges Google-robot segítségével és a Google IP-címéről nézze meg az oldalt. Ezt úgy teheti meg, hogy bedobja az URL-t a Google Rich Results Testbe. A Google egy feltérképező robotot küld a Google IP-címéről, és ha van valami a szerveren (vagy egy CDN-en), amely noindexet mutat, akkor ez elkapja azt. A strukturált adatok mellett a Rich Results teszt a HTTP-választ és a weboldal pillanatképet is megadja, amely pontosan azt mutatja, hogy a szerver mit mutat meg a Google-nak.
Amikor lefuttat egy URL-t a Google bővített eredmények tesztjén, a kérés:
- A Google adatközpontjaiból származik: A bot tényleges Google IP-címet használ.
- Átmegy a fordított DNS-ellenőrzéseken: Ha a szerver, a biztonsági beépülő modul vagy a CDN ellenőrzi az IP-címet, az visszakerül a googlebot.com vagy a google.com címre.
Ha az oldalt a noindex blokkolja, az eszköz nem tud strukturált adatokkal kapcsolatos eredményeket szolgáltatni. Meg kell adnia az „Oldal nem használható” vagy „A feltérképezés sikertelen” állapotot. Ha ezt látja, kattintson a „Részletek megtekintése” linkre, vagy bontsa ki a hibaszakaszt. Valami ilyesmit kell mutatnia: „Robots meta tag: noindex” vagy „noindex” észlelve a „robots” metacímkében.
Ez a megközelítés nem küldi el a GoogleBot felhasználói ügynököt, hanem a Google-InspectionTool/1.0 felhasználói ügynök karakterláncot használja. Ez azt jelenti, hogy ha a szerverblokk IP-cím alapján történik, akkor ez a módszer elkapja.
Egy másik szempont, amelyet ellenőrizni kell, ha egy hamis noindex címke kifejezetten a GoogleBot blokkolására van írva, továbbra is meghamisíthatja (utánozhatja) a GoogleBot felhasználói ügynök karakterláncát a Google saját User Agent Switcher bővítményével a Chrome-hoz, vagy beállíthat egy olyan alkalmazást, mint a Screaming Frog, hogy azonosítsa magát a GoogleBot felhasználói ügynökkel, és ennek meg kell fognia azt.
Képernyőkép: Chrome User Agent Switcher

Phantom Noindex hibák a Search Console-ban
Az ilyen típusú hibák diagnosztizálása fájdalmas lehet, de mielőtt felemelné a kezét, tartson egy kis időt, hogy megbizonyosodjon arról, hogy az itt vázolt lépések bármelyike segít azonosítani a probléma rejtett okát.
