
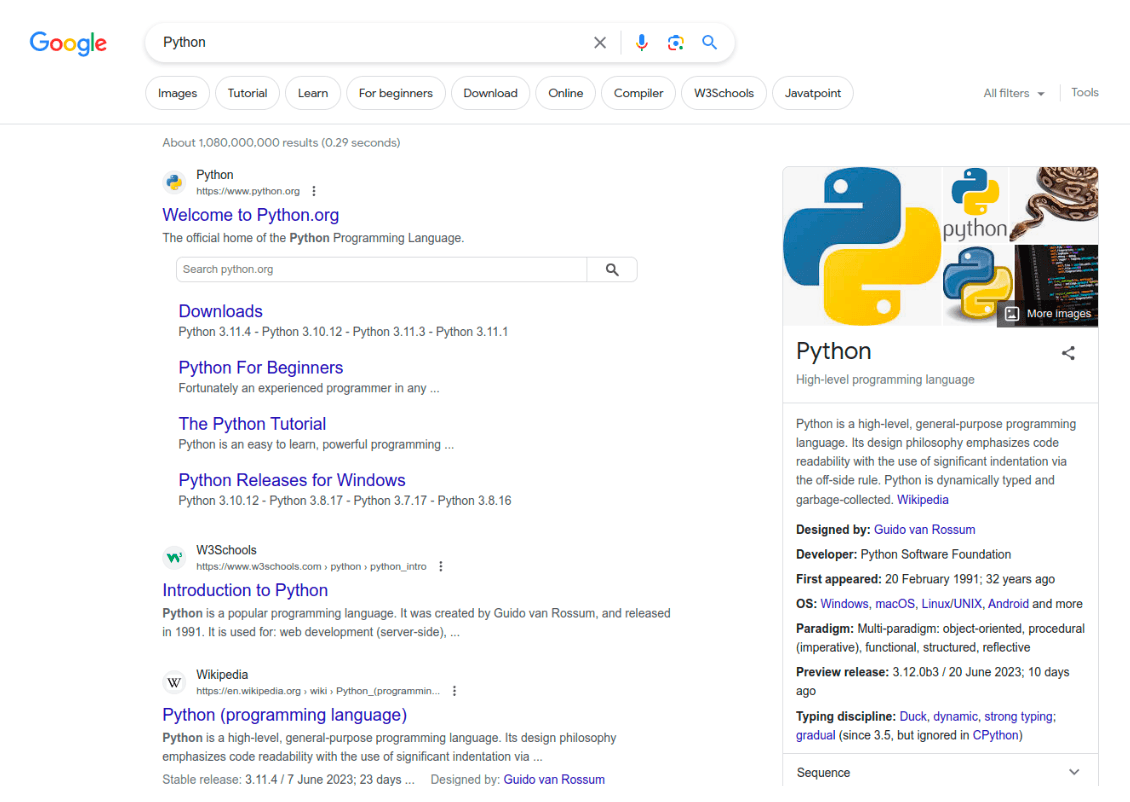
A Google Search a világ egyik vezető keresőmotorja, amely naponta közel 7 milliárd keresési lekérdezést tud végrehajtani.
Több milliárd oldalt tartalmaz, fürtözött adatbázisok felhőjében indexelve. Ezek az adatok számos célra hasznosak lehetnek, amelyeket a következő szakaszokban tárgyalunk.
Ebből az oktatóanyagból megtudhatja, hogyan gyűjtheti össze a Google keresési eredményeit. Az útmutató leírja, hogyan használhatja a Pythont a keresési eredmények elemzéséhez és a szükséges adatok kinyeréséhez. Olvass tovább.
A Google Keresésben lemásolható adattípusok
A Google keresési eredményoldala rengeteg információval gazdagodik. Számos tényező – keresési kifejezés, hely, eszköz stb. – határozza meg, hogyan fog kinézni a felhasználó képernyőjén.
Sőt, a Google Keresés hatalmasat fejlődött a 90-es évek vége óta. Ha eleinte csak linkeken tudott navigálni, most már a motor különböző típusú adatokat is szolgáltat, például képeket, videókat, könyveket stb.
Ennek megfelelően a Google Keresőoldalak lemásolásából származó kulcselemek a következők:
1. Keresési eredmények
A keresőoldal a legrelevánsabb keresési eredményeket tartalmazza relevancia szerint rangsorolva. Minden eredményhez tartozik egy link, egy cím és egy rövid leírás, ha elérhető. Ezek az adatok könnyen lekaparhatók.

2. Kapcsolódó keresések
A keresési eredményeken kívül a Google Keresés a kapcsolódó keresési lekérdezéseket is megjeleníti. Ezek az információk hasznosak lehetnek különböző, de releváns keresési kifejezés-ötletek generálásához.

3. Rangsorolás
Egy másik kulcsfontosságú elem, amelyet a Google Keresés adatainak lekaparásakor kaphat, a rangsorolás. A keresési eredmény rangsorolása is kulcsfontosságú.
Segít megérteni a tartalom relevanciáját, és ez az egyik fő mérőszám, amelyet a SEO szakértők figyelembe vesznek stratégiáik megvalósítása során.

4. Kiemelt kivonatok
Néhány konkrét és gyakori keresési lekérdezéshez a Google Keresés egy rövid részletet is biztosít. Ez egy módszer a kérdés hatékonyabb és dinamikusabb megválaszolására definíciók, listák, táblázatok stb. segítségével.

5. Szűrt keresési eredmények
A keresési eredmények a következő típusú találatok alapján is szűrhetők: Képek, Videók, Hírek, Térképek, Könyvek, Pénzügy stb. Ez a funkció hasznos lehet az információk finomhangolásához és szűkítéséhez.

Miért fontosak és hasznosak ezek az adatok?
A Google keresési eredményeinek lemásolása számos bevételtermelő folyamathoz felhasználható. Használható például piackutatásra, versenytársak elemzésére, termékfejlesztésre, SEO optimalizálásra, tartalomkészítésre, reklámkampány-elemzésre stb.
A lekapart adatok okos felhasználásával a vállalkozások javíthatják üzleti tevékenységüket és versenyelőnyre tehetnek szert.
A Google Keresés kaparása Eredmények
Most, hogy egy kicsit több információval rendelkezünk a Google Keresésről és annak különféle funkcióiról, nézzük meg, hogyan lehet ezeket összegyűjteni.
Ebben a szakaszban megtudhatja, hogyan állíthat be egy Google Kereső kaparót a kulcsszó használatával Piton.
Kezdje a szükséges függőségek telepítésével és a környezet beállításával. Ezt követően olyan összetettebb elemeket fedezhet fel, mint például a HTTP-kérések, elemzések, oldalszámozás és egyebek.
1. A környezet beállítása
A Google keresési eredményeinek lemásolása a környezet beállításával kezdődik. A következőképpen teheti meg:
- Látogassa meg a hivatalos weboldal a Python legújabb verziójának letöltéséhez és telepítéséhez.
- Futtassa a következő parancsot a terminálon a szükséges függőségek telepítéséhez:
| pip telepítési kérések bs4 |
Ez a parancs telepíti a kéréseket és Gyönyörű leves modulok, amelyek szükségesek a folytatáshoz. A kérések modulra a GET kérések küldéséhez van szükség, míg a Beautiful Soup hasznos lesz az adatok elemzésénél.
2. HTTP kérések készítése
Kezdje azzal, hogy használja a kérések könyvtárat, és küldjön GET-kérést a Google Keresésnek. Először is importálja a könyvtárakat:
| import kéréseket -tól bs4 import Gyönyörű leves |
Ezután használhatja a kap() kérés benyújtásának módja:
| search_term = „Python” válasz = requests.get(„https://www.google.com/search?q={}”.formátumban(keresés _term)) print(response.status_code) |
Ne feledje, hogy az eredményt a válaszobjektumban tárolja, és kinyomtatja az állapotkódot. Ha a fenti kódot futtatja, láthatja a 200-as kimenetet.
Ennek ellenére valószínűleg 429 túl sok kérés állapotkódot fog kapni, mivel a Google úgy azonosítja, hogy ez a kérés egy robottól származik.
Ebben az esetben úgy kell módosítanunk a kódunkat, hogy a Google ne robotként tekintsen ránk.
3. User-Agent hozzáadása
A User-Agent beállításával ideiglenesen megkerülheti a fenti hibát. A User-Agent közli a Google Keresővel, hogy melyik böngészőről és eszközről fér hozzá.
Térjen vissza ahhoz a részhez, ahol azonosította a keresési kifejezést, és adja hozzá a User-Agentet a kérések fejlécéhez az alábbiak szerint:
| ua = „Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, mint a Gecko) Chrome/114.0.0.0 Safari/537.36″ fejlécek = { „Felhasználói ügynök”: ua } search_term = „Python” page = „https://www.google.com/search?q={}”.format(search_term) válasz = requests.get(oldal, fejlécek=fejlécek) |
Mint látható, a kap metódus egy további paramétert vesz fel fejlécekamely segítségével egyéni felhasználói ügynököt állíthat be diktálja.
4. Proxyk hozzáadása
Egy egyéni User-Agent működhet kisebb kereséseknél, de amikor elkezd nagyot lépni, a Google Kereső ismét blokkolni kezdi a kérést.
Ez az oka annak, hogy a keresési eredmények lekaparásakor proxykat kell használnia, és gyakran forgatnia kell őket a CAPTCHA-védelem megkerüléséhez.
Mindezek manuális elvégzése nehézkes lesz, és kevés vállalat közelíti meg ezt így. Ehelyett igénybe veheti a prémium proxyszolgáltatásokat, hogy elvégezze helyetted a kemény munkát.
Számos megoldás létezik, de az egyik leginkább ajánlott az Oxylabs Web Unblocker. Kifejezetten nehéz célokat szem előtt tartva tervezték, és rendkívül könnyen megvalósítható.
Mivel jelenleg ingyenes próbaverziót kínálnak, ennek segítségével alaposan teszteljük a kaparót.
Miután regisztrált, és megkapta az alfiók hitelesítő adatait a Web Unblocker Proxyhoz, a meglévő kód egyszerű módosításával használhatja proxyját.
| felhasználónév, jelszó = „FELHASZNÁLÓNÉV”, „JELSZÓ” proxy = { ‘http’: ‘http://{}:{}@unblock.oxylabs.io:60000’.format(felhasználónév, jelszó), ‘https’: ‘http://{}:{}@unblock.oxylabs.io:60000’.format(felhasználónév, jelszó) } |
Lássuk, mi történt a fenti kódban. Két változót hozott létre az alfiókja felhasználónevével és jelszavával. Ön hozta létre a proxyt is diktálja ezeket a hitelesítő adatokat használva.
Ezt követően átadhatja a proxyk a kap() módszer egy másik kiegészítő paraméterként.
| válasz = requests.get(oldal, fejlécek=fejlécek, proxyk=proxy, verify=False) |
És ennyi! A Web Unblocker automatikusan elforgatja a proxykat, így nem kell manuálisan megtennie.
A proxykat azonban manuálisan is elforgathatja a proxy IP-címek listájának megszerzésével, és úgy konfigurálhatja őket, hogy véletlenszerű vagy rögzített időközönként működjenek.
5. A keresési eredmények elemzése
Az elemzés a kimásolt adatok szerkezetének átalakítását jelenti, hogy olvasható legyen. Miután elküldte a HTTP-kérést, és megkapta a választ, meg kell találnia a módját, hogy az adatokat használható formátumba helyezze.
Ha Pythonnal kapar, a megoldás a Beautiful Soup könyvtár lesz. Ez egy Python-könyvtár, amelyet gyakran alkalmaznak adatok HTML-ből való kinyerésére.
Az indításhoz írja be a következő parancsot:
| leves = Gyönyörű leves(válasz.tartalom„html.parser„) |
A leves az objektum tartalmazza az elemzett Google keresési eredmény HTML-oldalát. Most egy böngésző segítségével ellenőrizze a HTML-oldalt.
Észre fogja venni, hogy az összes keresési eredmény a div közös osztállyal g. Tehát fogjuk meg ezeket a diveket a mind_kereső módszer:
| eredményeket = leves.mind_kereső(„div„, {„osztály„:„g„}) |
Most egyszerűen ismételheti a diveket, és egyenként elemzi az összes keresési eredményt.
| adatok = ()számára eredmény be eredmények: title = result.find(“h3”).text url = result.find(“a”).attrs(“href”) description = „”elem = result.find(„div”, {„class”:”lEBKkf”}) ha elem: span = elem.find(„span” ha span: leírás = span.text nyomtatás (cím, URL, leírás) data.append({ ‘title’: cím, ‘url’: url, „description”: leírás, }) |
Ezenkívül a keresési eredmények a listán belül lesznek tárolva adat és minden eredményért kap egy diktálja tárgyat tartalmazó cím, leírásés url.
| 📝 Jegyzet: Ha szeretné megkönnyíteni a folyamatot, automatizálhatja az elemzést harmadik féltől származó eszközök használatával. Tekintse meg a 10 leghatékonyabb adatelemző eszköz listáját, amelyek közül választhat. |
6. Lapozás kezelése
Ha több mint tíz keresési eredményt szeretne elérni, oldalszámozást kell használnia. A Google Kereső egy táblázatot tartalmaz a következő oldalakról, amelyeket felhasználhat erre a célra.
Először meg kell ragadnia a táblázatot az alábbi kóddal:
| tds = soup.find(„asztal”, {„osztály”: „AaVjTc”}).find_all(„td”) oldalak = (td.find(‘a’)(‘href’) számára td be tds ha td.find(‘a’)) |
Mostantól adatokat gyűjthet le ezekről az oldalakról az egyes oldalak iterálásával és elemzésével az alábbiak szerint:
| számára oldalon be oldalak: válasz = requests.get(“https://www.google.com{}”.format(oldal), fejlécek=fejlécek, proxyk=proxy-k, ellenőrzés=hamis) leves = BeautifulSoup(response.content, „html.parser”) eredmények = soup.find_all(„div”, {„class”:”g”}) számára eredmény be eredmények: cím = eredmény.find(“h3”).szöveg url = result.find(„a”).attrs(„href”) elem = eredmény.find(„div”, {„osztály”:”lEBKkf”}) ha elem: span = elem.find(„span” ha span: leírás = span.text nyomtatás (cím, URL, leírás) data.append({ ‘title’: cím, ‘url’: url, „description”: leírás, }) |
Következtetés
A Google Keresés adatainak összegyűjtése nagyszerű lehetőség lehet a piaci trendekkel, a versenytársakkal, az ügyfelek igényeivel, a termékekkel kapcsolatos információk megszerzésére, stb. Segítségével értékes betekintést nyerhet, és versenyelőnyt szerezhet.
Az ebben a cikkben ismertetett technikák használatával könnyedén lekaparhatja a Google keresési adatait, és nagyszerű üzleti döntések meghozatalára használhatja őket.
