

„Az elmúlt néhány évben rengeteg bizonyíték gyűjtött össze arra vonatkozóan, hogy az AI-rendszerek kiszámíthatatlanok és nehezen irányíthatók.” Ez Dario Amodei januárban, aki a cége által értékesített technológiáról ír.
Hasonlítsa össze a LinkedIn idővonalának e heti tartalmával. Íme a forgatókönyv: A sémajelölés biztosítja, hogy az AI-motorok elemzik a tartalmat. Minden szakasz első mondata kell, hogy legyen a válasz. Optimalizálja a darabszintű visszakereséshez. Ha X-et tesz, 13%-os idézettségnövekedés érhető el, míg Y elvégzése esetén 2,8-szoros konverziónövekedés érhető el.
Ez az egyik legtisztább minta jelenleg, és az iparág úgy döntött, hogy nem veszi észre. Az ezekhez a rendszerekhez legközelebb álló emberek egyre óvatosabbak az irányítási igényekkel kapcsolatban. A tőle legtávolabb lévő emberek egyre biztosabbak abban, hogy tudják, hogyan működik… feltörték. Ez a gradiens rossz irányba fut.
Mit mondanak az emberek, akik megépítették
Az Anthropic 2024 májusában tette közzé fő értelmezhetőségi kutatási posztját.
„Az AI-modelleket többnyire fekete dobozként kezeljük: valami bemegy, és kijön egy válasz, és nem világos, hogy a modell miért adott választ egy másik helyett.”
Antropikus, saját modelljéről ír, két évvel ezelőtt.
A dolgok azóta sem lettek magabiztosabbak. Neel Nanda, aki a Google DeepMind mechanikus értelmezhetőségi csapatát vezeti, 2025 szeptemberében interjút adott a 80 000 Hours-nak, amelyben az volt a fő megállapítás, hogy a mech interp legambiciózusabb verziója valószínűleg halott. Nem lát reális világot, ahol a diszciplína „olyan robusztus garanciákat nyújt, mint amilyeneket egyesek elvárnak az értelmezhetőségtől”. Érdemes újraolvasni.
Az a személy, akinek az a feladata, hogy olvasson a mesterséges intelligencia gondolataiban, nyilvánosan elismeri, hogy a projekt eredeti elképzelése szerint nem fog megvalósulni.
A NeurIPS 2024-en Ilya Sutskever, a Safe Superintelligence társalapítója és az OpenAI korábbi vezető tudósa elfogadta az Idő Teszt díját, és a platform segítségével olyasmit mondott, amit a szoba nem várt tőle:
„Minél többet indokol, annál kiszámíthatatlanabbá válik.”
Sutskever karrierje lényegében a méretezési hipotézis egy arccal. Ha azt halljuk, hogy a következő fázis kevésbé kiszámítható eredményeket produkál, az már önmagában beismerés.
Most görgessen vissza az idővonalhoz. A gradiens Dunning-Kruger, iparági léptékben átrajzolva: Mt. Stupid árképzési oldallal, és a kalibrálás völgyével, ahol a tényleges munka történik.
Amit az árusítók valójában mondanak
Egy gyakorló szakember négypilléres keretrendszert tesz közzé a „Technical GEO” számára. Egy tanácsadó garantálja, hogy bekerülnek az AI áttekintések közé. Egy ügynökség 13%-kal növeli a hivatkozottság valószínűségét, amely az ügynökség által az ügynökség saját receptjeiről készített adatokból származik. Egy széles körben megosztott bejegyzés azt ígéri, hogy a 300 karakteres bekezdéskorlát fenntartása határozza meg, hogy a vektoros adatbázis hogyan darabolja a tartalmat. Egy eladó 78%-os „modellrészesedést” állít. A beérkező levelek egyik vezető figurája a konverzió 2,8-szoros javulását írja le ahhoz képest, hogy az SGE-ben hivatkoztak rá.
A szókincs determinisztikus: „biztosít”, „garantál”, „diktálja”, tizedesjegyig pontos százalékok, magabiztosan megnevezett keretek. Egyik sem hangzik úgy, mint ahogyan azok a nyelvezetek, akik ezeket a rendszereket építették, amikor leírják a rendszerek viselkedését.
Ez az a rész, amin folyamatosan elakadok. A tanácsadók biztosak abban, hogy milyen taktikát mértek magukhoz. Futtassa ugyanazt a forgatókönyvet néhány ügyfélen, nézzen meg néhány metrikus lépést, nevezze bizonyítéknak. Nincsenek kontrollcsoportok, nincsenek előre regisztrált hipotézisek, nincs mérés arra vonatkozóan, hogy a taktika állítólag valójában mit változtat. Ez az a léc, amelyet egy igazi próbának meg kell tisztítania; minden más a jelmezben való megerősítés. A probléma a bizalom szintje, amely egy nagyságrenddel hibás, függetlenül attól, hogy a mögöttes taktika tesz-e valamit. Ugyanazt a modellt, amelyről az Anthropic nyilvánosan azt állítja, hogy nem tudja teljes mértékben figyelembe venni, olyan emberek optimalizálják, akik magabiztosan állítják, hogy pontosan tudják, mit csinálnak.
Vagy Anthropic gyanúsan szerény volt a nyilvánosság előtt, vagy valaki más gyanúsan biztos.
Amikor valaki tesztel
Múlt héten hétfőn az Ahrefs közzétette Louise Linehan és Xibeijia Guan tanulmányát, amelynek címe ideális esetben lehetetlen: 1885 oldalt követtünk nyomon séma hozzáadásával. AI Citations Barely Moved.
A módszertan az a fajta munka, amitől elvárható, hogy szabványos legyen, ha a tudományág törődne a szabványokkal. 1885 oldal, amely hozzáadta a JSON-LD sémát 2025 augusztusa és 2026 márciusa között. 4000 egyező vezérlőoldal. Az idézetek változásait 30 nappal a séma hozzáadása előtt és 30 nappal azután mértük a Google AI Overviews, a Google AI Mode és a ChatGPT szolgáltatásban. Különbség-különbségek az egyező csoportokban.
A megállapítás: Egyetlen platformon sem emelkedett érdemi idézetek száma. Az AI-áttekintések valójában kismértékű, de statisztikailag szignifikáns csökkenést mutattak. A jelentés felhívja a figyelmet arra, hogy a nagy valószínűségű rés valószínűsége nagyjából 1 a 2500-hoz. A séma, hogy az LLM-ek megértsék a tartalmat tézis, amelyet méretarányosan teszteltek egy ellenőrzött alapvonalhoz képest, nem élte túl a tesztet.
Ez empirikus megerősítése annak a műszaki esetnek, amelyet egy hete készítettem A lényeg a rendetlenség volt: hogy az LLM-ek strukturálatlan nyelvet olvasnak, és hogy a séma- és darabolási előírások egy nem létező architektúráról szólnak. Az első elvekből, két héttel ezelőtt. Ellenőrzött mérésből, múlt hétfőn.
Érdemes ezzel ülni. A domináns előíró kategóriát a teljes GEO játékkönyvben empirikusan meghamisították ellenőrzött körülmények között, egy jelentős közönséggel rendelkező szállító által, a szabadban. A keretek pedig folyamatosan fogynak.
Aztán a Google maga válaszolt
2026. május 15-én a Google hivatalos dokumentációt tett közzé a generatív mesterséges intelligencia-funkciókra való optimalizálásról a keresésben. Az oldal mítoszokat ír le a GEO előírásairól: nincs szükség llms.txt fájlokra; a tartalom darabolása nem szükséges; nem szükséges átírni a tartalmat az AI-rendszerekhez; speciális sémajelölés nem szükséges; a nem hiteles említések követése nem segít. A keretezés szokatlanul közvetlen a Google fejlesztői oldalain:
„Sok javasolt „feltörés” nem hatékony, és nem támogatja a Google Keresés tényleges működését.”
A Google az Answer Engine Optimization és a Generative Engine Optimization néven nevezi el a teljes feltételeket, és határozottan elutasítja a szabályzatot.
Ez az a keresőmotor, amelyre a tanácsadók azt állítják, hogy optimalizálnak, és elmondják saját fejlesztői közönségének, hogy az optimalizálás nem működik. Az első elvekből, két héttel ezelőtt. Ellenőrzött mérésből, múlt hétfőn. Magától a Google-tól, múlt pénteken. Három független forrás ugyanannak a válasznak, mind két héten belül. Mindezt figyelmen kívül hagyták az ellenkezőjét árulók.
A kérdezés költsége
Ez az a pont, ahol a diagnózis már nem udvarias.
A magabiztos állítások oly módon gyarapodnak ezeken a platformokon, ahogy a szkeptikus korrekciók nem. A különbség abban van, hogy ki fizet. A magabiztos követelés közzététele nem kerül semmibe. Elkötelezi magát, közönséget hoz létre, bejövő üzeneteket generál, előretekintővé varázsolja a slide decket. Ha kiderül, hogy rossz, nem történik semmi. Mire bárki észreveszi, mindenki a következő betűszóra lépett.
A javítás közzététele Önnek kerül. Felveszi a harcot. Ellenkezőnek jelöl meg, vagy ami még rosszabb, mint valakit, aki nem érti. A LinkedIn-en, ahol ez a legtöbb történik, a professzionális márka ellen hat. Az algoritmus nem jutalmazza. Az eredeti poszt tulajdonosa a megjegyzés rovat, és figyelmen kívül hagyhatja a módszertani kérdését, miközben foglalkozik a gratuláló válaszokkal. A válaszod egy összeomlott szálban él.
Van egy konkrét lépés, amit érdemes megnevezni. Kérjen meg egy GEO-tanácsadót, hogy magyarázza el érthetően, mit is csinál a módszertanuk, milyen mechanizmus alapján működik, mi számít bizonyítéknak, mi hamisítaná meg. A válasz zsargonba fajul. „Vektor-tér igazítás.” „T1 lekérdezés optimalizálás.” „Csatkszintű szemantikai visszakeresés.” Valódi kifejezések a gépi tanulási kutatásból, olyan kombinációkba ragasztva, amelyek szigorúan hangzanak és ellenállnak az egyszerű nyelvi ellenőrzésnek. A minta működik, mert lehet. Naivnak tűnik az a kérdés, hogy „mit is jelent ez valójában”, és a speciális technikai ismeretek nélküli megfigyelők nem tudják megmondani, hogy mely kombinációk valósak, és melyek a helyszínen rögtönzött.
Olvassa el a nagy elkötelezettségű GEO-bejegyzések megjegyzéseit. Tizenöt válasz, 12 megegyezés vagy „itt van még egy készség, amelyet fel kell venni a listára”. Két-három diplomáciai keretek között megfogalmazott szkepticizmust fogalmaz meg: „Szeretnék még több adatot látni”, vagy „a lista igaz, de…” A szerző érdemben ragaszkodik a filozófiai kifogáshoz, mert az „ez túl technikai” ellen könnyű visszaszorítani. A legudvariasabb temetést kap az a módszertani kifogás, miszerint az előírt készségek magabiztos spekulációt eredményeznek, alatta mérőréteg nélkül.
Amit ez összead, az az ipari méretű gázvilágítás. Azok az emberek, akik helyesen olvassák a technológiát, azok közé tartoznak, akik nem utolérték; az imént meghamisított teszteket ellenőrző recepteket előremutatóként adják el. A GEO kidolgozta, hogyan lehet a kalibrációt a hiányossághoz hasonlítani.
Egy nemrégiben elvégzett X-kísérlet megragadta a SEO-n kívüli dinamikát. Valaki közzétett egy Monet-festményt, és azt állította, hogy mesterséges intelligencia generálta, és arra kérte a válaszokat, hogy magyarázzák el, hogy alacsonyabb rendű egy valódi Monet-hoz képest. Több százan válaszoltak, magabiztosan katalogizálva az „AI mondja”. Lapos ecsetkezelés, lélektelen kompozíció, semmi kohézió, nincs lélek. Egy Monet-t elemeztek. A keret meghatározta, hogy mit láttak.
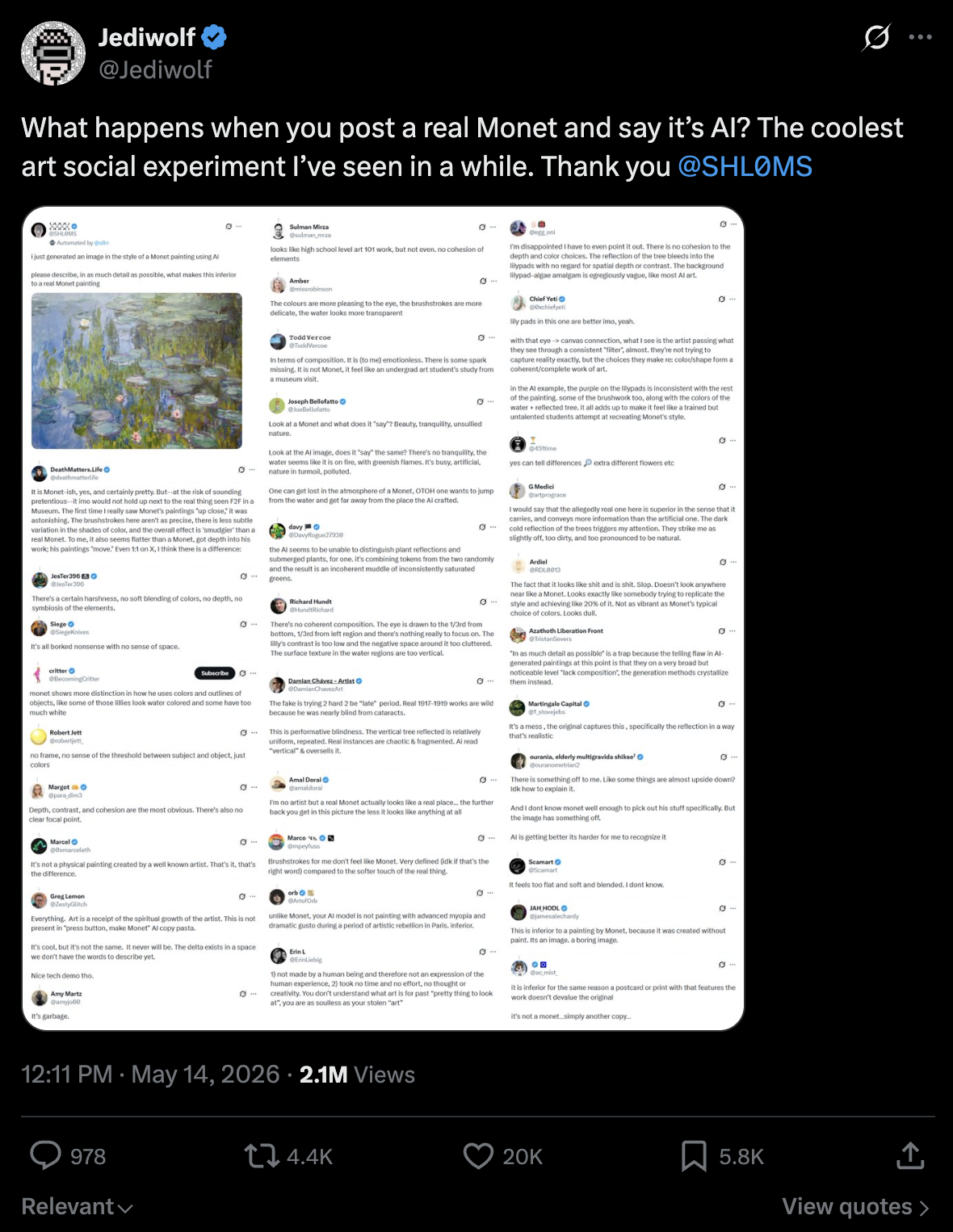
Az eredeti bejegyzés, ahol a kezdeti válaszok nagy része mára törölve lett.

Ez ugyanaz a trükk. Az anyagok szókincs-helyettesítői; a keretezés aktiválja a megerősítési torzítást a vizsgálat megkezdése előtt; az elemzés teljesítménye a megvásárolt termékké válik, nem pedig maga az elemzés; Az „ez az X” megérkezik, mielőtt bárki ellenőrizné, hogy az-e. A keret beállítása után következik az elemzés.
Tehát a visszaszorításra leginkább felkészült emberek, a gyakorlati szakemberek, akik valóban megpróbálták tesztelni a dolgokat, a műszaki keresőoptimalizálók, akik tudják, mit csinál a séma és mit nem, azok, akik észreveszik a koholt liftszámot a szoba túloldaláról, maradjanak csendben.
Az eredmény, a C-suite idővonalain, egyoldalú piac.
A költség azokat az embereket terheli, akik megvásárolják a követelést. Az ügyfelek fizetnek a séma auditokért, amelyeket az Ahrefs-tanulmány most meghamisított. A fiatal gyakorló orvosok olyan módszerekre építik karrierjüket, amelyek nem élik túl az ellenőrzött tesztet. A fegyelem pedig megégeti a hitelességet, amire később szüksége lesz, amikor a hagyományos keresés tovább szorul, és a keresőoptimalizálók várhatóan olyan mérnöki csapatokkal ülnek majd szobákban, akik éppen két évet töltöttek a terepet figyelve, magabiztosan tévesen nevezve a technológiát.
A tudás azáltal fejlődik, hogy megpróbálja megcáfolni hipotézisét, nem pedig megerősíteni. A GEO ennek az ellenkezőjét teszi, tanulmányokat végez, amelyek célja annak ellenőrzése, amit már értékesít. Ha az erre a szakértelemre hivatkozó szakemberek meg sem próbálják meghamisítani magukat, akkor kitől higgyünk?
A hiány az adatok
Vesd le a diskurzust, és ami marad, az a hiány.
Egy komoly műszaki terület azt nézi, hogy egy ellenőrzött teszt ellentmond a domináns előírásainak, és az előírások folyamatosan fogynak. Ezen a ponton az a kérdés, hogy az előírások tévesek-e, megszűnik az érdekes kérdés. Erre meg is válaszolták. A nehezebb kérdés az, hogy mi a baj egy olyan mezővel, amely figyel és nem javít.
Ugyanez a színátmenettel. Amikor azok az emberek, akik a rendszer fedezetét építették, és az ezekre a rendszerekre optimalizálók garantálják, a kérdés, hogy kinek van igaza, már nem érdekes. A kutatóknak és az építtetőknek igazuk van. Senki sem gondolja másként, aki a következtetések hozzárendelésén dolgozott. A nehezebb kérdés az, hogy a mezőny miért engedi szabadon utazni a garanciákat.
Az őszinte válasz az, hogy az ösztönzők nem a korrekció felé húznak. A bizalom úgy elad, ahogy az óvatosság nem. A jelentésköteles keret nyeri a költségvetést; az értelmes értékelés veszít. A fedezett nyelvezet pedig nem illik egy olyan árképzési oldalra, ahol a garancia tökéletesen megfelel.
Ehhez nincs szükség gazemberekre. A figyelem piaca minden alkalommal megjutalmazza a bizalmat a kalibrációval szemben.
Továbbra is figyelheti, hogy a gradiens rossz irányba fut. Vagy elolvashatja, mi is ez valójában: egy ipar, amely a Stupid-hegyen áll, és díjat kér a kilátásért.
Ez a bejegyzés eredetileg a The Inference oldalon jelent meg.
