

Növelje készségeit a Growth Memo heti szakértői betekintéseivel. Iratkozz fel ingyen!
A keresőoptimalizálók évek óta egy egyszerű feltevés alapján működnek: Minél jobban lefedi a tartalom, annál valószínűbb, hogy a mesterséges intelligencia által generált válaszokban megjelenik. Valójában a klasszikus SEO-tartalom minden „bevált gyakorlata” több felé tolja Önt: több altéma, több szakasz, több szó. Építsd meg a „végső útmutatót”.
A 815 000 lekérdezés-oldal pár elemzése 16 851 lekérdezés és 353 799 oldal között mást mond:
- A fan-out lefedettség szinte irreleváns az idézettség szempontjából.
- Két jel jelzi, hogy a ChatGPT idézi-e az Ön oldalát.
- Hat konkrét változtatás a meglévő tartalomkönyvtárban, súgó.
1. A tanulmány
Az AirOps 16 851 lekérdezést futott le a ChatGPT-n keresztül háromszor a felhasználói felületen keresztül, rögzítve minden kimerítő allekérdezést, minden keresett URL-t, minden idézetet és minden oldalt. Oshen Davidson építette a vezetéket. elemeztem az adatokat.
Minden lekérdezés átlagosan két kiugró lekérdezést generál. A ChatGPT alkeresésenként nagyjából 10 URL-t kér le, végigolvassa őket, majd kiválasztja, hogy melyiket kívánja idézni. A bge-base-en-v1.5 beágyazások koszinusz-hasonlóságát használva értékeltük, hogy az egyes oldalak H2-H4 alcímei mennyire egyeznek a kinyíló lekérdezésekkel. Ezt a pontszámot hívjuk légterelő lefedettség: azon altémák aránya, amelyekkel egy oldal 0,80-as hasonlósági küszöb mellett szól. (A 0,80-as hasonlósági küszöbértéket használták annak eldöntésére, hogy egy alcím egyezésnek számít-e egy kibővített lekérdezéssel. Tekintse ezt relevanciasávnak.)
A kérdés: A nagyobb lefedettségű oldalakat többször idézik?
Még több információt találhat a közösen írt AirOps jelentésben.
2. A sűrűség alig mozgatja a tűt
A 815 484 soron keresztül gyenge a kapcsolat a rajongói lefedettség és az idézettség között.
Az altémák 100%-os lefedése 4,6 százalékponttal növeli az egyiket sem. Ez a különbség tovább csökken, ha Ön szabályozza a lekérdezés egyezését (az oldal legjobb címsora mennyire egyezik az eredeti lekérdezéssel). Az erős lekérdezési egyezésű oldalak között (>= 0,80 koszinusz hasonlóság):
A mérsékelt lefedettség (26-50%) felülmúlja a teljes lefedettséget. A mindent lefedő oldalak alacsonyabb pontszámot érnek el, mint azok, amelyek az altémák negyedét fedik le. A „végső útmutató” stratégia rosszabb eredményeket produkál, mint egy fókuszált cikk, amely két-három kapcsolódó szempontot jól lefed.
3. Ami valójában előrejelzi az idézetet
Ez a két jel dominál: a lekérdezési rang és a lekérdezés egyezése.
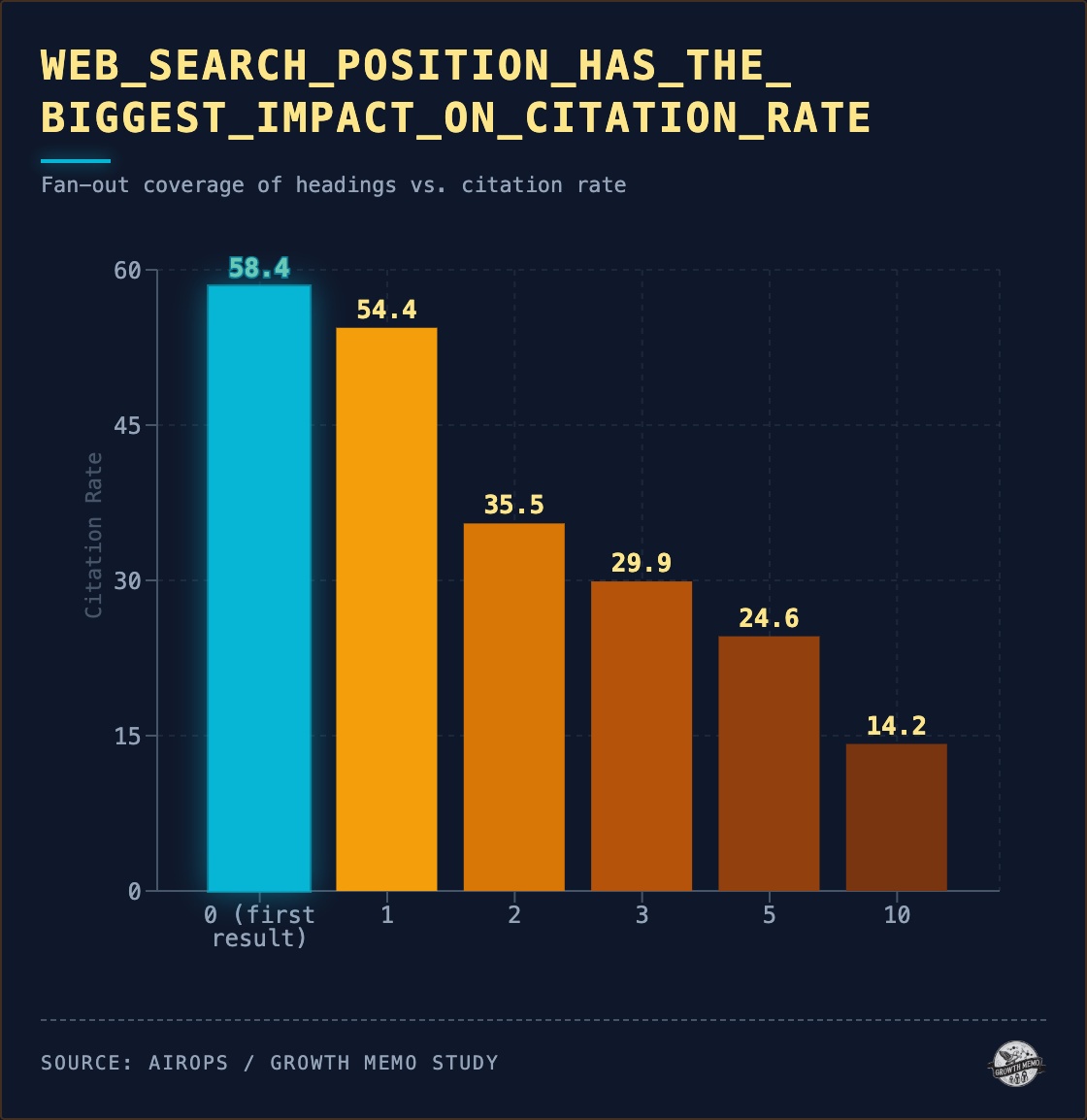
1. Visszakeresési rang nagy különbséggel a legerősebb előrejelző. A ChatGPT internetes keresési eredményei között a 0. helyen lévő oldal (a keresőeszköz által visszaadott első URL) 58%-os hivatkozási arányt mutat. A 10. pozícióban ez 14%-ra csökken. Az elemzéshez minden promptot háromszor futtattunk le egymás után, és a mindhárom futtatás során idézett oldalak medián visszakeresési rangja 2,5. Soha nem hivatkozott oldalak: medián 13.
2. Lekérdezés egyezés (a lekérdezés és az oldal legjobb címsora közötti koszinusz hasonlóság) a legerősebb tartalomjel. A 0,90+ címsoregyezésű oldalak hivatkozási aránya 41%, szemben a 0,50 alatti oldalak 30%-os arányával. Még a legjobban rangsorolt oldalak (0-2. pozíció) között is a magasabb keresési egyezés 19 százalékponttal növeli.
Fan-out lefedettség, szószám, címsorszám, domain jogosultság: mind másodlagos. Némelyik lapos. Némelyik fordítottan korrelál.
4. A Wikipédia-kivétel
Az egyik webhelytípus megtöri a mintát. A Wikipédiának van a legrosszabb lekérdezési rangja az adatkészletben (medián 24), és a legalacsonyabb a lekérdezés egyezési pontszáma (0,576). Még mindig eléri a legmagasabb idézési arányt: 59%.
A Wikipédia oldalain átlagosan 4383 szó, 31 lista és 6,6 táblázat található. Szó szerint enciklopédikusak. A ChatGPT a keresési eredmények mélyéről idézi a Wikipédiát, ahol minden más webhelytípus figyelmen kívül marad.
Ez a sűrűség jelként működik, de olyan léptékben, amelyet egyetlen kiadó sem képes replikálni. A Wikipédia tartalma kimerítő, gazdagon strukturált, és több millió témához kapcsolódik. Egy 3000 szavas céges blogbejegyzés 15 alcímmel nem ugyanaz.
5. A bimodális valóság
Ebben az adatkészletben a ChatGPT által lekért oldalak 58%-át soha nem idézik. 25%-át mindig idézik, amikor megjelennek. Csak 17% esik a kettő közé.
A mindig idézett és soha nem idézett csoportok a legtöbb tartalmi mérőszámon közel azonosnak tűnnek: hasonló szószám (~2200), hasonló címsorszám (~20), hasonló olvashatósági pontszám (~12 FK-osztály), hasonló tartományi jogosultság (~54). Az általunk mérhető oldalon megjelenő jelek nem választják el a nyerteseket a vesztesektől.
Ami elválasztja őket, az a visszakeresési rang. A mindig idézett oldalak a csúcs közelében helyezkednek el, amikor megjelennek. A soha nem hivatkozott oldalak az alsó felében helyezkednek el. A visszakereső rendszer, bármilyen belső jelet használ is, a kapuőr. Minden más döntetlen.
6. Mit jelent ez a tartalom szempontjából
A hagyományos SEO tartalomírási bölcsesség azt mondja, hogy fedj le több altémát, adj hozzá több szakaszt, építs sűrűséget. Az adatok szerint a hagyományos megközelítés „vegyes” oldalakat hoz létre, a középső 17%-ot néha idézik, máskor figyelmen kívül hagyják.
A vegyes oldalak rendelkeznek a legtöbb szószámmal, a legtöbb címsorral és a legmagasabb tartományi jogosultsággal az adatkészletben. Ők a „végső útmutatók”. Ők a legkevésbé megbízható teljesítményt nyújtók a ChatGPT-ben.
A következetesen nyerő oldalak koncentráltak. Azok:
- Párosítsa a lekérdezést közvetlenül a fejlécükben,
- Általában rövidebb (az idézet édes pontja 500-2000 szó), és
- Legyen elegendő szerkezete (7-20 alcím) a tartalom hígítás nélküli rendszerezéséhez.
Építsd meg azt az oldalt, amelyik a legjobb válasz egy kérdésre. Nem az az oldal, amely megfelelően válaszol a 20-ra.
