
A webkaparás kihívást jelent – különösen dinamikus webhelyek esetén. Ezek a webhelyek valós idejű frissítéseket és interaktív funkciókat jelenítenek meg, így a felhasználók jobb böngészési élményt nyújtanak. Az ilyen tulajdonságok azonban megnehezítik a kaparók számára az adatgyűjtést.
Az a jó, hogy a Python segíthet. Ez a programozási nyelv lehetővé teszi szkriptek létrehozását a webhelyek automatikus vezérléséhez. A Python és könyvtárai segítségével könnyedén lekaparhatja az adatokat még dinamikus webhelyekről is.
Olvassa tovább, hogy megtanulja, hogyan lehet dinamikus webhelyet létrehozni Python segítségével.
🔑 Kulcs elvitelek
- A dinamikus webhelyek valós idejű, interaktív tartalmat kínálnak, míg a statikus webhelyek stabil, változatlan tartalommal rendelkeznek.
- A Python az egyszerűsége és a különféle könyvtárakkal való kompatibilitása miatt ajánlott webkaparáshoz.
- Az összetett tartalom, az IP-blokkolás, az elemészlelés és a lassú teljesítmény bonyolultabbá teheti a dinamikus webkaparást.
- Fontolja meg a JavaScriptet, mint alternatívát a rendkívül interaktív, dinamikus weboldalak lekaparására.
Mi az a dinamikus webhely?
A dinamikus webhely egy interaktív tartalommal rendelkező weboldalgyűjtemény. Az ilyen típusú webhelyek valós idejű adatokat jelenítenek meg, vagy a felhasználó számára releváns frissítéseket jelenítenek meg – például tartózkodási helyét, életkorát, nyelvét és böngészési tevékenységét.
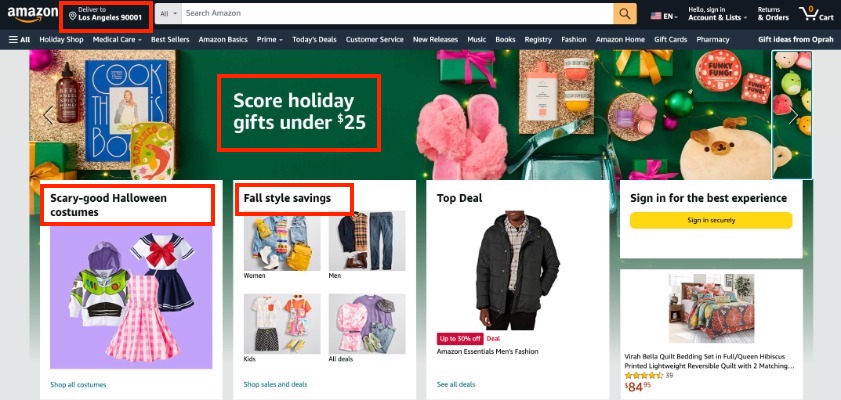
A dinamikus webhelyek leggyakoribb példái a közösségi média és az e-kereskedelmi platformok. A Twitter hírfolyamod azonnal megjeleníti a követett fiókok legújabb bejegyzéseit. Ezenkívül az Amazonon látható termékek általában a legutóbbi vásárlásokon és a keresési előzményeken alapulnak.
Nézze meg az alábbi fotót, hogy megtudja, hogyan frissíti az Amazon a kezdőlapját, hogy a felhasználóhoz kapcsolódó szezonnak és ünnepnek megfelelő eredményeket jelenítsen meg.

Statikus és dinamikus webhelyek
A dinamikus webhelyekkel ellentétben létezik egy másik típus is, az úgynevezett statikus weboldalak. A valós idejű adatokról ismert dinamikus webhelyekkel ellentétben a statikus webhelyek stabil tartalommal rendelkeznek. Minden felhasználó ugyanazt fogja látni minden alkalommal, amikor belép az oldalra. A brosúrák és a csak olvasható webhelyek azok a tipikus statikus webhelyek, amelyeket naponta látunk.
A legtöbb statikus webhely nem igényel túlzott háttérfeldolgozást. A weboldalak tartalma már előre HTML és CSS segítségével készült, ami azt jelenti, hogy egyetlen statikus webhely sem tölti be azt, amire a felhasználónak szüksége van.
A statikus telek könnyebben és olcsóbban megépíthető, mint legalább 1000 dollárra lesz szüksége egy dinamikus webhely létrehozásához a saját. A dinamikus webhelyek azonban jobbak a felhasználói élmény és a funkcionalitás szempontjából. A webhely látogatói személyre szabottabb és interaktívabb böngészést kapnak a dinamikus webhelyeken.
| 📝 Megjegyzés A két típus közötti különbségek ellenére a dinamikus webhelyek tartalmazhatnak statikus weboldalakat. A statikus webhelyek dinamikus tartalmat is tartalmazhatnak. Az olyan oldalak, mint a használati feltételek és szabályzatok, általában statikusak, de jelen lehetnek egy dinamikus webhelyen. Eközben az űrlapok, naptárak és multimédiás tartalmak dinamikusak, és hozzáadhatók egy statikus webhelyhez. |
Könnyebb lekaparni a statikus webhelyeket, mivel a tartalom állandó, míg a dinamikus tartalom interaktív jellege megnehezíti a lekaparást.
A kaparók azonban továbbra is élvezik az információk kinyerését a dinamikus webhelyekről a birtokukban lévő értékes adatok miatt.
Előtt
Követelmények a dinamikus webhelyek kaparásához
Kulcsfontosságú a dinamikus webhelyek kaparásakor használandó megfelelő eszközök ismerete. Íme a feladat elvégzéséhez szükséges dolgok:

1. Kódszerkesztő
A kódszerkesztőben létrehozhat egy szkriptet a lemásolási folyamat automatizálásához. Bármilyen kódszerkesztőt használhat, de erősen ajánlott a Visual Studio Code és a Sublime Text.
2. Python
A Python ideális a webkaparáshoz, mivel egyszerű szintaxisa van, amelyet még a kezdők is megértenek. A legtöbb kaparó könyvtárral és modullal is kompatibilis.
| 📝 Megjegyzés Mindig használja a Python legújabb verziója. Ez biztosítja, hogy minden szükséges könyvtár és modul működjön. |
3. Szelén
Szelén egy Python-könyvtár, amely a legjobban használható dinamikus tartalom webkaparására. Ez a modul lehetővé teszi a böngésző műveleteinek automatizálását, időt és erőfeszítést megtakarítva ezzel.
4. WebDriver
Ehhez a feladathoz WebDriverre lesz szüksége. Ez az eszköz API-kat kínál, amelyek lehetővé teszik parancsok futtatását a cél dinamikus webhelyével való interakcióhoz.
A WebDriver segítségével betöltheti és szerkesztheti a tartalmat kaparáshoz. Az összegyűjtött adatait akár olvashatóbb formátumba is átalakíthatja.
| ✅ Pro tipp Győződjön meg arról, hogy a WebDriver kompatibilis a böngészővel, hogy elkerülje a lekaparási folyamat során felmerülő problémákat. Megteheti töltse le a ChromeDrivert ha Google Chrome-ot használ. |
5. GyönyörűLeves
Gyönyörű leves egy másik Python-könyvtár, amely elemzi a HTML-t és az XML-t. A Selenium segítségével a BeautifulSoup elemezni tudja a dinamikus webhelyek DOM-struktúráit és navigálhat a között.
6. Proxy szerver
A proxy használata a kaparás közben előnyös, különösen akkor, ha dinamikus webhelyekkel dolgozik. A proxyk elfedik az Ön tényleges IP-címét azzal, hogy lehetővé teszik egy másik IP-cím használatát. Ezzel elkerülheti az esetleges IP-blokkolásokat.
Miután biztosította az előfeltételeket, elkezdheti a weboldalak kaparását a Python segítségével. A következő részben megtudhatja, hogyan kell ezt megtenni.
7. Dinamikus webkaparás Python segítségével szelén használatával

Akár kezdő, akár szakértő, bárki képes dinamikus weboldalakat kaparni Python segítségével a Selenium és a BeautifulSoup segítségével. Kövesse az alábbi lépéseket:
1. lépés: Telepítse a Selenium modult a Pythonhoz. Ezt a parancsot használhatja számítógépe termináljában vagy parancssorában:
pip install selenium
2. lépés: Töltse le a WebDriver futtatható fájlját.
3. lépés: A kódszerkesztőben hozzon létre egy Python-fájlt. Importálja a modulokat, és hozzon létre egy új böngészőt.
4. lépés: Írja be az illesztőprogram eszközének elérési útját a „<útvonal az illesztőprogramig>” mezőbe.
from selenium import webdriver driver = webdriver.Chrome(executable_path= ‘<path-to-driver>’)
5. lépés: Keresse meg a lemásolni kívánt webhelyet. Változás ‘
driver .get(‘<websites-url>’)
6. lépés: Használja a böngészőt az oldalon lévő dolgok megkereséséhez. Egy táblázat megkereséséhez használhatja a HTML-címkéjét vagy valamelyik attribútumait.
Például, ha egy táblának van egy azonosítója „táblázat-adatok”, keresse meg ezzel a paranccsal:
table = driver.find-element-by-id(‘table-data’)
7. lépés: Miután megtalálta a táblázatot, elkezdheti az adatok kaparását. A BeautifulSoup segítségével olvassa be a táblázat adatait.
Telepítse a BeautifulSoup-ot a terminálba vagy a parancssorba a következő szkript segítségével:
pip install beautifulsoup
8. lépés: Importálja az eszközt, és elemezze a táblázat HTML-kódját.
from bs4 import BeautifulSoup soup = BeautifulSoup(table.get.attribute(‘outerHTML’), ‘html.parser’)
9. lépés: Szerezze be az információkat a táblázat soraiból és celláiból.
rows = soup.find-all(‘tr’)
data = ( )
for row in rows:
cells = row.find-all( ‘td’ )
row-data = ( )
for cell in cells:
row-data.append(cell.text.strip())
data.append(row-data)
10. lépés: Nyomtassa ki a kinyert információkat.
for row-data in data:
print(row-data)
Nyugodtan próbálja ki a fenti lépéseket különböző dinamikus tartalmakkal és webhelyekkel. Nézze meg az alábbi videót, hogy jobban megértse az egész folyamat működését:
A dinamikus webhelyek lekaparásának kihívásai
A rendszeres tartalomváltások mellett itt vannak a dinamikus webhelyek kaparásának fő kihívásai:

Komplex dinamikus tartalomkaparás
A dinamikus webhelyek csak az oldal betöltése után tudnak tartalmat generálni, ami megnehezíti az adatok lekaparását. Előfordulhat, hogy a tartalom első betöltésekor nem állnak rendelkezésre a szükséges információk.
Lehetséges IP-blokkolás a webhelyekről
A webhelyek CAPTCHA-t használnak, vagy blokkolják az IP-címeket, hogy megakadályozzák a túlzott kaparást. Egyes webhelyek még a földrajzi blokkolást is kikényszerítik. Az ilyen biztonsági intézkedések korlátozhatják a tartalomhoz való hozzáférést.
| ✅ Pro tipp Az IP-blokkolások elkerülése érdekében használjon proxyszervert. Ha egy megbízható szolgáltatótól szerez proxyt, szinte minden országból és városból használhat IP-címeket, így csökken az IP-blokkolások esélye. |
Specifikus elemek észlelése
A dinamikus webhelyeken bizonyos elemek megtalálása és lekaparása kihívást jelenthet a folyamatosan változó tartalom miatt.
Lassú teljesítmény
A dinamikus tartalom webes lekaparása lassú lehet, mivel meg kell várnia, amíg a webhely megjeleníti a lemásolni kívánt információkat. A folyamat tovább késik, ha hatalmas adatkészleteken dolgozik.
| ✅ Pro tipp A Python mellett JavaScriptet is használhat dinamikus weboldalak kaparására. A legtöbb aktív webhely JavaScriptet használ, így ez jó alternatíva a különböző weboldalakon található interaktív tartalmakhoz. |
Következtetés
Az adatok lemásolása dinamikus webhelyekről interaktív és valós idejű jellegük miatt kihívást jelenthet. A Python azonban eszközeivel és könyvtáraival segít ennek megkönnyítésében.
A kódolási készségekkel, speciális eszközökkel és a webhelyszerkezetekkel kapcsolatos ismeretekkel dinamikus webhelyeket gyűjthet össze, és valós idejű adatokat gyűjthet.
GYIK
-
A dinamikus webhelyek gyorsabbak, mint a statikus webhelyek?
A statikus webhelyek általában gyorsabbak, mint a dinamikus webhelyek, mivel nem igényelnek annyi feldolgozást a tartalom megjelenítéséhez. A dinamikus webhelyeknek a helyszínen kell lekérniük és előállítaniuk az adatokat, ami lelassíthatja a betöltési időt.
-
Kimutatható a webkaparás?
Igen, a webkaparást a webhely rendszergazdái észlelhetik. Szokatlan mintákat vehetnek észre, például túl sok kérés érkezik egy helyről.
-
A webkaparás károsíthatja a webhelyet?
Ha túlzottan vagy agresszíven kapar egy webhelyet, az károsíthatja azt. Lelassítja a webhelyet, és összeomlik.
-
Miért dinamikus webhely a Netflix?
A Netflix egy dinamikus webhely, mert gyakran változtatja és frissíti a tartalmát a felhasználók által megtekintett tartalmak és preferenciáik alapján.
