

Amikor ügyfelei kérdeznek valamit a ChatGPT-től vagy a Geminitől, a modell csendesen elindít egy hagyományos webes keresést a háttérben, lekéri a rangsoroló oldalakat, és ezekből szintetizálja a választ. A rejtett lekérdezéseket rangsoroló webhelyeket idézik. Akinek nem, az ne tegye. A QueryFan személyre szabott promptokat generál, végigfut mindkét modellen, és rögzíti az egyes kiváltott kereséseket. Ez a lista a valódi mesterséges intelligencia láthatósági célpontja. Ez ingyenes.
A kulcsszavak listája hasznos, csak a kép fele hiányzik
Hadd legyek pontosabb, mielőtt valaki dühös választ ír.
A „kulcsszavak” kifejezést az „egyszeri” lekérdezésekre használom, amelyek a hagyományos keresőmotorokba kerülnek. Igen, tudom, hogy több mint egy évtizede egy „szemantikai” világban élünk, de állapodjunk meg a terminológiában, amelyet egyelőre mindenki követhet.
A „kulcsszólisták” elsődleges kérdése az AI-kereséssel összefüggésben három részből áll:
- Az LLM-ekhez kapcsolódó lekérdezések (promptok) általában hosszabbak, sokrétűek és beszélgető jellegűek. A hagyományos keresések általában szűkebbek.
- A hagyományos keresés „egyszeri”. Végezze el a keresést, megszerezze az információkat, majd végezzen egy másik független keresést. Az LLM-ekkel kapcsolatos lekérdezések/kérések általában beszélgető jellegűek, és a korábbi tokenek kontextusát hordozzák.
- Az LLM-ek webes kereséshez használt mechanizmusai személyre szabott kontextust is hordoznak. Ha a felhasználó korábban kijelentette, hogy vegán, és erről megkérdezi az LLM-et [running shoes]nagyon valószínű, hogy az LLM keresést fog végezni ennek érdekében.
Lényegében az AI-keresés egyfajta „univerzális szándékú dekóder” lett a felhasználók számára. Az AI-val folytatott nagy, sokrétű beszélgetések megoldható lekérdezések részhalmazaira bomlanak, amelyek a háttérben „hagyományos” keresésként futnak a Google-on vagy a Bing-en, és az eredményül kapott webhelyeket használják fel a válasz generálására. A folyamat „Retrieval Augmented Generation” (RAG) néven ismert.
Az optimalizálási cél elmozdult. Már nem kizárólag arra optimalizálsz, amit az emberek beírnak egy chat-boxba. Arra optimalizál, amit az AI-ügynök csendben keres a nevükben, a háttérben, anélkül, hogy a felhasználó tudná, hogy ez történt.
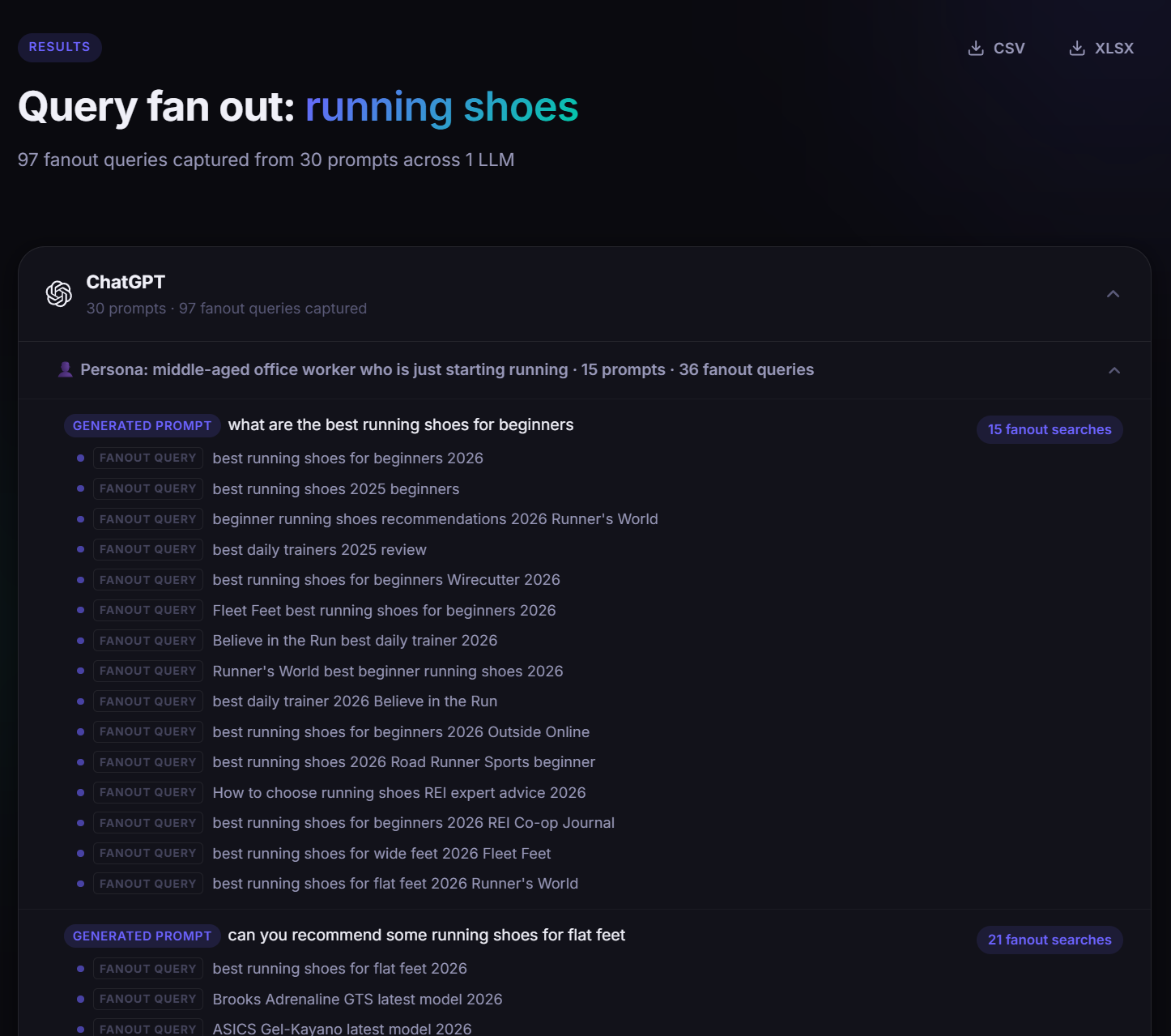
Ezeket a háttérlekérdezéseket rögzíti a QueryFan. Ezek gyakran egészen eltérnek attól, amit a felhasználó valójában kérdezett. És ezek azok a dolgok pontos listája, amelyeket rangsorolnod kell ahhoz, hogy megjelenjen az AI által generált válaszokban.
A kiállítás: Reddit leesett egy szikláról egy kedden
Ennek a titkos kapcsolatnak a hatóköre és mélysége akkor vált világossá, amikor a Reddit felhőtlen láthatóságnövekedésnek örvendett a Google-ban, és 2026. szeptember 10-én tragédia történt. A PromptWatch idézetkövetési adatai szerint a Reddit idézési aránya a ChatGPT-válaszokban szinte egyik napról a másikra összeomlott. Az összes idézet 15%-a volt. Napokon belül 2% alatt volt.
Az ok nem volt elbűvölő: a Google csendben megszüntette a 100 keresési eredmény egyidejű lekérésének lehetőségét (a num=100 paraméter) a keresési API-ból azon a napon.

Gondold át, mit mond ez neked. A Reddit láthatósága a ChatGPT-válaszokban nyomon követve A Google tömeges keresési lehetőségeinem semmi, amit a Reddit csinált, nem edzésadatok frissítése, sem igazítási módosítás. A következmény körülbelül olyan finom, mint egy leejtett zongora: a ChatGPT tömegesen gyűjtötte a Google keresési eredményeit, a Reddit uralta akkoriban ezeket a találatokat, és amikor a tömeges lehívás eltűnt, a Reddit hivatkozásai is eltűntek.
A mesterséges intelligencia keresési felületei nagyrészt a hagyományos keresés köré épülnek. Az „AI” bit valódi (a szintézis, a személyre szabás, a beszélgetési koherencia), de a információkeresés lépés rendkívül ismerős. A Google indexeli és rangsorolja az internetet; az AI ezt az indexet vizsgálja. A tartalmat továbbra is rangsorolni kell.
Hogyan működik a QueryFan

1. lépés: Az Ön „hagyományos” kulcsszavai
A „futócipő” kifejezés hagyományos kulcsszólistája tartalmazhatja ennek a kifejezésnek a különféle javasolt változatait, olyan forrásból, mint a Google Suggest.

A QueryFan esetében egyszerűen a „futócipő” témát használhatjuk, és ezt használhatjuk első lépésként, mivel ezzel kapcsolatos promptokat fogunk generálni.
2. lépés: Határozza meg a személyeket
Az Ön személyei alapján fogjuk személyre szabni az általunk generált promptokat. Ez megváltoztatja a token tér bejárását, igazodva a több millió közösség képzési adataihoz, fórumbejegyzésekhez, Reddit-szálakhoz és internetes diskurzusokhoz, ahol a valódi felhasználók valódi kérdéseket tesznek fel ezekkel az identitásokkal.
A QueryFan elküldi a személy + téma kombinációját az LLM-nek, hogy olyan kérdéseket generáljon, amelyeket a személy valójában feltenne egy AI-eszköznek. Nem kulcsszavak. Kérdések. Valódi, beszélgetős, kontextussal terhelt kérdések. A [middle-aged vegan man who just started running] például olyan dolgokat fog produkálni, mint:
- „Melyik vegán futócipő jó azoknak a középkorú férfiaknak, akik most kezdenek el futni?”
- „Hol vásárolhatok vegán futócipőt online az Egyesült Királyságban?”
- „Mire kell figyelnem, amikor kezdőként kiválasztom az első futócipőmet?”
3. lépés: LLM kiválasztása és a szintén kért gazdagítás
AI beszélgetések ága. Valaki, aki a vegán futócipőkről kérdez, további kérdéseket tesz fel: a költségekkel, a márkákkal, a sérülések megelőzésével kapcsolatban. A QueryFan átadja a generált promptokat az AlsoAsked API-n keresztül, hogy rögzítse a legközelebbi szándékú nyomon követési kérdéseket mindegyik körül. A People Is Ask adatok a megfelelő eszköz itt, mert a kérdés közelségének modellezésére készült, amelyre pontosan szüksége van, amikor meg akarja jósolni, hogy a beszélgetés merre halad tovább.
Például, ha az Egyesült Királyságban a „futócipők” kifejezésre keresnek rá, bizonyos márkákra vonatkozó utólagos kérdéseket, a cipőválasztás módját, sőt gyakori orvosi kérdéseket is felvetnek.

Azt is kiválaszthatja, hogy a ChatGPT-t, a Geminit vagy mindkettőt szeretné-e használni. Mindegyik LLM kissé eltérően kezeli és terjeszti ki a lekérdezéseket, így ha egy adott platformra optimalizál, a legjobb, ha onnan szerzi be az adatokat.

4. lépés: A Fan-Out lekérdezése
A QueryFan elküldi a bővített prompt listát a GPT-5-nek, ahol engedélyezve van a webes keresés (az OpenAI Responses API-n keresztül), és a Gemininek, ha a Google Search földelés aktív (a Gemini Grounding API-n keresztül). Mindkét modell, amikor úgy dönt, hogy egy felszólításhoz aktuális információkra van szüksége, tényleges Google-keresést hajt végre a színfalak mögött.
Ez a folyamat rögzíti a fan-out lekérdezéseket, mivel mindkét API – meglehetősen hasznos – átlátható arról, hogy mit keresett. A Gemini API visszaadja a webSearchQueries tömb a groundingMetadata minden megalapozott válasz mezője. Az OpenAI Responses API naplózza a tényleges keresési lekérdezéseket a web_search_call kimenet. A QueryFan mindkettőt begyűjti.
Az eredmény egy táblázat: személy-specifikus promptok, a tényleges Google keresési lekérdezések, amelyeket az AI lőtt ki. Nem az, amit az ügyfele beírt. Amit az AI keresett a nevükben. Ezek az Ön új keresőoptimalizálási céljai, és ez idáig nem volt ingyenes eszköz, amely ezeket nagymértékben felszínre hozná.
Az alapkérdés: Nem minden felszólítás indít el keresést
Egy rövid, de fontos figyelmeztetés, mielőtt mindent keresőoptimalizálási lehetőségnek minősítene.
Nem minden felszólítás készteti az AI-t webes keresés végrehajtására. A modellek a token előrejelzés konszenzusa alapján döntenek arról, hogy szükség van-e élő információra.
Például: „Mit csinálnak a vörösvérsejtek?” nem indít el keresést. Ennek az az oka, hogy van egy nagyon meredek haranggörbe, amelyből a következő tokenek fognak megjelenni. A több milliárd képzési dokumentumban a válasz nagyon stabil maradt, így magabiztosan generálható a „modellben” válasz.
A skála másik végén egy kérdés, például „Mi történt ma a hírekben?” internetes keresést indítana el. Nagyon lapos görbe lenne a „wtf tokenek következnek?”, mivel nincs „stabil” válasz a betanítási adatokon belül; mindig változik, élő adatokat igényel. Ez a Query Deserves Freshness (QDF) koncepció egy másik változata, amelyet a keresőoptimalizálók évek óta használnak.
Ha érdekli az alapozás, Dan Petrovic kiváló munkát végzett ezen a területen, és még képzett modelleket is közzétett az Hugging Face-en, hogy megjósolja, vajon a lekérdezések megalapozottak lesznek-e, ha elérik a bizalmi küszöböt.

A QueryFan feltárja, hogy melyik kéri az elindított keresést, és melyik nem. Csak a megalapozottak (azok, amelyek ténylegesen elindították a Google-keresést) használhatók a SEO-n keresztül. A modellen belüli válaszok egyelőre nem érhetők el. Be kell hatnia a képzési adatokra, hogy oda mozgassa a tűt, ami egy teljesen más projekt, sokkal hosszabb horizonttal.
Mit csinál az eredményekkel
Mostantól megvan a tényleges keresési lekérdezések listája, amelyeket a mesterséges intelligencia eszközei indítanak el, amikor megválaszolják az adott személy kérdéseit. Futtasson le egy szabványos hézagelemzést:
- Az alábbi lekérdezések közül melyikhez van tartalom?
- Melyiket rangsorolod már?
- Melyeknek nincs lefedettsége a webhelyén vagy bárhol, ahol valószínűleg megemlítik?
Az első két kategória diagnosztikus. A harmadik az akciólista.
Egy fontos különbség a hagyományos SEO-tól: Az Ön saját A rangsorolás nem az egyetlen út az AI láthatóságához. Az LLM-ek átvizsgálják a legjobb 10, 20, néha 50 találatot egy megalapozott lekérdezésért, és szintetizálják azokat. A 3. helyen álló megbízható áttekintő webhely jogos útja a mesterséges intelligencia által generált válaszban való megjelenéshez, még akkor is, ha a saját domain soha nem kerül az első oldalra. Ha egy terméket felülvizsgálnak egy nagy tekintélyű szakértő webhelyen, megemlítenek egy összefoglaló cikkben, megjelennek a releváns közösségi tartalomban, ezek mind számítanak.
Az LLM láthatósága több helyszínre összpontosít. Ez azt jelenti, hogy a hiányelemzésnek két kimenete van: a létrehozandó tartalom a saját webhelyénés a kereshető elhelyezések mások webhelyein.
A Punchline
Fordítsa vissza gondolatait arra a Reddit idézési grafikonra. Az, amelyik leesett egy szikláról, amikor a Google egyetlen API-paramétert megváltoztatott. Egy teljesen független vállalat AI láthatósága nyomon követte egy olyan keresési API viselkedését, amelyet nem irányított, és valószínűleg nem is tudott a létezéséről.
Ez a függőség formája. És ez nem az, hogy a SEO halott; ennek majdnem az ellenkezője. A SEO most egy további eltávolítással működik: ahelyett, hogy az emberi lekérdezésre optimalizálna, az AI által lefordított lekérdezésre kell optimalizálnia, amely az ember és a Google között történik.
A QueryFan módot ad arra, hogy megtudja, mit eredményez valójában a fordítás. A kulcsszólista megmondja, hogy az emberek mit írtak be a keresősávba. A QueryFan elmondja, hogy a ChatGPT és a Gemini mit keresett a nevükben a háttérben, anélkül, hogy bárki megkérné, hogy jelentse be.
Ezek különböző listák. A köztük lévő szakadék nem csekély finomítás a tartalomstratégián. Az AI-keresésnek ez az a része, amelyet senki sem mért, mert senkinek sem volt ingyenes eszköze a méréshez.
Közzététel: A szerző a Queryfan alkotója.
Ezt a bejegyzést eredetileg a Mark Williams-Cook Substack oldalán tették közzé.
